
Current impacts of AI on Technology Delivery
In this post we are going to look at some of the ways in which AI and data science is impacting the practical delivery of technology solutions today. To be clear from the outset, this will not include a discussion of future-looking topics that have been getting coverage recently such as fully automated code generation or algorithmic product development, etc. Rather, we will be looking the impacts which are already happening right now, the consequences of which are often just as significant albeit in different ways.
Strategic Alignment Model
To get a clearer idea of what is going on, it will be helpful to start by reviewing the dramatic shift that has occurred recently within the discipline of data engineering. In order to do that, we are going to use a version of Niel Nickolaisen’s Strategic Alignment Model, which is one of our most frequently utilised tools in the inception phases of data programs.
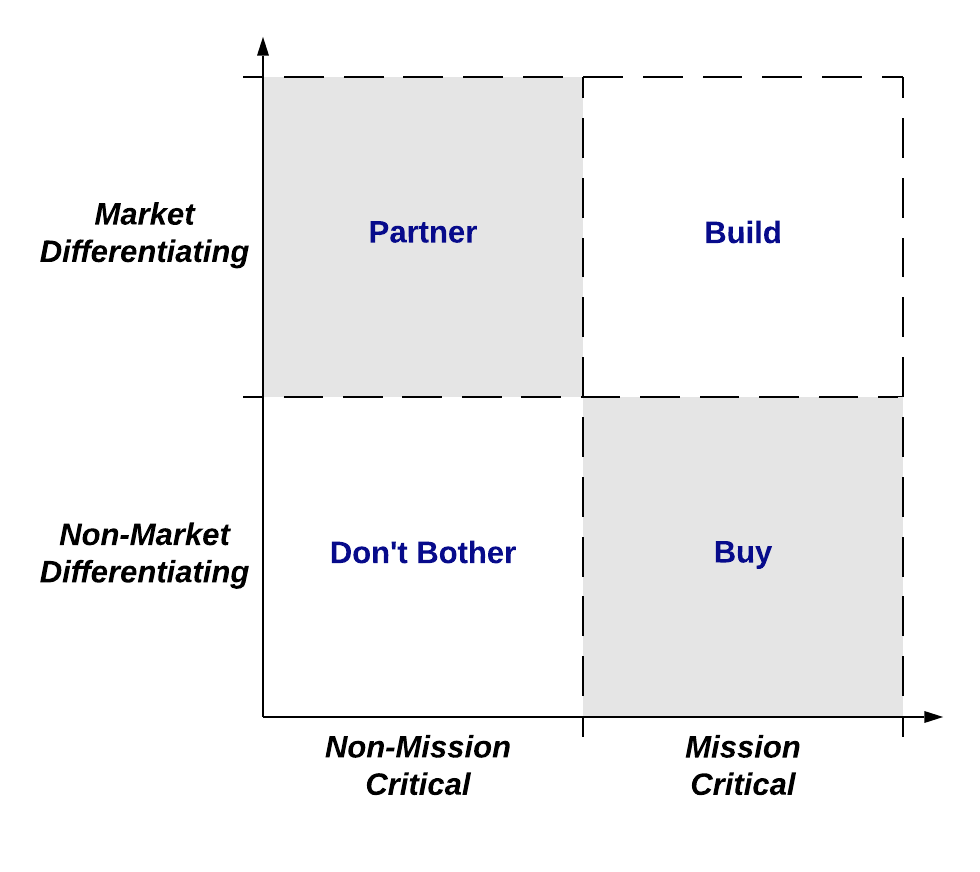
It splits an organisation’s capabilities in two core dimensions:
1. Whether or not they are market differentiating
2. Whether or not they are mission critical core competencies
This then informs technology delivery strategy as follows:
· Systems which deliver business capabilities which are mission-critical market-differentiators you are going to need to build - as by definition there will be no commoditised solution available yet otherwise it wouldn’t be a differentiator - and you are going to need to build them very well whilst effectively managing risk and uncertainty, as this is where your future revenue streams are coming from (as a side note, this quadrant represents almost all of our consulting work).
· Systems which deliver business capabilities which are mission-critical but not market-differentiators should be bought in. That’s because they are generally commoditised solutions to common problems (ERP, payroll, invoicing, etc), hence re-inventing those solutions is a pointless waste of money. In some cases, organisations might have non-standard workflows which don’t match commodity solutions, but in the long run it is almost always better to change those workflows rather than build bespoke software.
· Systems which deliver business capabilities which are not mission-critical but are market-differentiating are generally good candidates for partnerships, i.e. with businesses for whom the newly developed capabilities will become core competencies.
· Systems which deliver business capabilities which are neither mission-critical nor market-differentiating should generally be avoided, as their value is as best highly questionable.
Such analysis frequently provides very useful insight to organisations. However, a critical point to remember is that markets are dynamic, so such categorisations are never fixed. Indeed, it is interesting to see how technologies traverse this diagram over time. The most common transition is from market-differentiator to non-market differentiator as technologies mature: new features and capabilities that were once enough to attract new customers and generate additional revenue become widely adopted, turning into commodity features that are required by any product attempting to enter the market or protect its existing revenue streams. There are also examples, such as online video within media organisations, which start out as non-mission critical differentiators before becoming mission-critical differentiators and then non-differentiating core competencies (as a side note, the other important shift as functionality matures from differentiating to non-differentiating is the associated switch in customer priorities from functional to non-functional requirements – what matters for non-differentiating systems is standards-compliance, portability and the avoidance of vendor lock-in, etc).
Data Engineering As Market Differentiator
So what does this have to do with data engineering? Well, the really interesting thing about the recent history of data engineering is that is represents the much less common example of a technology moving in the opposite direction – upwards, from non-differentiating to differentiating:
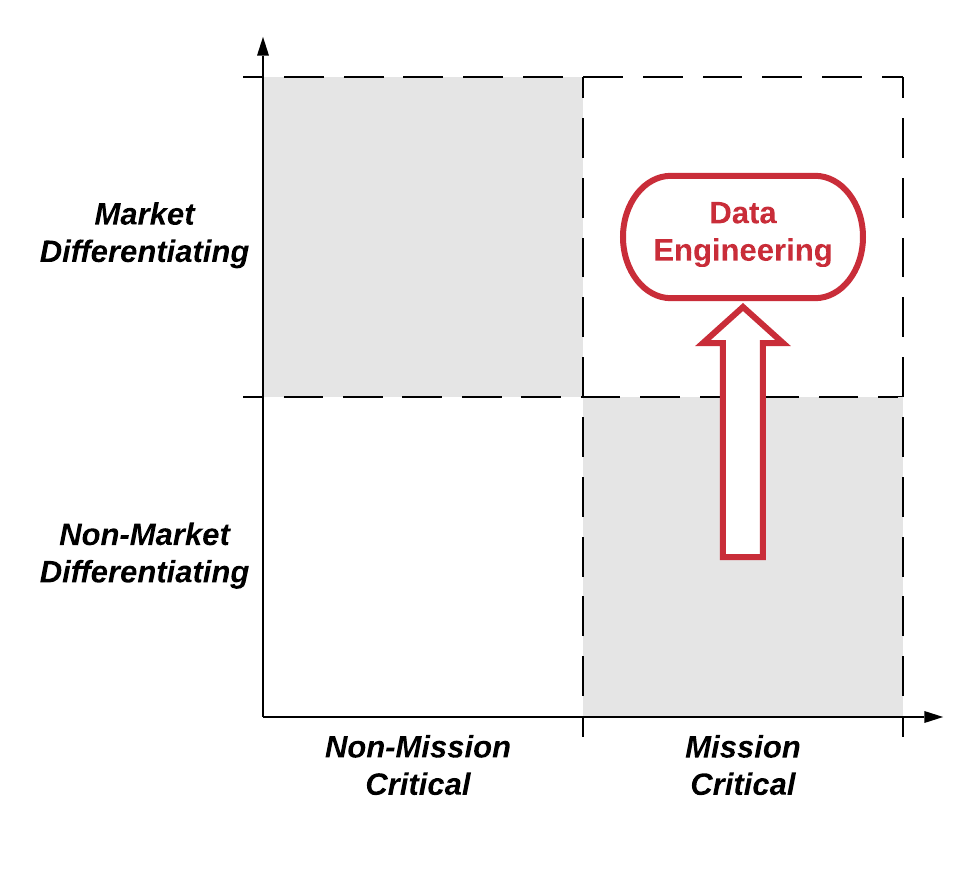
Data engineering used to be the domain of the back office: of ETLs, PL/SQL programming and cron jobs. It was one of the areas of software development most insulated from the market pressures which shaped agile software delivery techniques and lean product development. It was also one of the least impacted as a result: rare indeed was it to find an ETL developer writing their code test-first.
However, the revolutions in firstly data analytics and statistical software development, and then in machine learning techniques, have radically transformed the discipline and moved it front and centre in the new era of data-driven product innovation. This has created a sudden critical demand firstly for access to these new technologies, a need which has driven the recent adoption and growth of data science as a commercial capability; and secondly for the software development skills that allow innovative product ideas to be tested and iterated rapidly under conditions of uncertainty without incurring crippling amounts of technical debt.
One of the most prevalent organisational responses to these demands is for data-driven product delivery programs to employ three discrete technology functions:
1. Data science teams: typically, recent PhDs with good theoretical knowledge but little experience of commercial software development. They often work in what is effectively an R&D function developing prototype implementations in their preferred language.
2. Software delivery teams: where these function best, they are most typically staffed by experienced/senior developers well versed in extreme programming and continuous delivery techniques and ideally who have worked together previously (the importance of this last point is so often overlooked – no matter how good the individual members are, if the team itself is new then you are going to burn significant time and cash whilst relationships, trust and delivery flow are negotiated and established).
3. Machine learning engineering teams: who are responsible for taking the outputs of data science and adapting them into something which can be integrated by software delivery. I use the term “adapting” rather than “refactoring” here intentionally, as due to the “specialised” nature of the data science algorithms the aim is normally to add runtime tooling into a software execution wrapper that allows the prototype implementation to be invoked concurrently or to handle larger datasets. Most typically this will be suites of map-reduce and derivative tooling (not least because these teams are also the most natural home for data engineers who invested in Hadoop stack upskilling during the first data analytics revolution).
Implications for Software Architecture
This differentiation is having profound, and most highly undesirable, results. My colleague Fabio Colasanti has previously written persuasively about the consequences at the code level. In the rest of this article, we will explore the implications for software architecture, and the resulting impacts on the business value actually being realised by these programs of work.
Arbitrary Service Boundaries
Conway’s Law states that the architecture of systems tends to reflect the architecture of the organisations that build them. The most reliable way to mitigate this tendency is to create a single cross-functional delivery team that includes domain experts and works as close to customers as possible. That’s because the domain model and business capabilities encoded into software create the channels along which information flows and business value is then generated and delivered.
In the absence of such an integrated, cross-functional approach, the likely outcome will instead be an architecture where service boundaries reflect the arbitrary divisions of labour in the construction of the codebase. Is that really so bad? Well, yes actually - it is. Once the code sequences required to implement and integrate the business capabilities are defined, it becomes immediately apparent that the natural execution flow is being critically disrupted by meaningless service interfaces that require mapping layers, additional infrastructure complexity, kill performance, undermine cacheability, expose security vulnerabilities, and introduce a host of other avoidable problems.
In doing so, they also undermine the chances of a successful delivery. Successful technology delivery is ultimately a question of risk management: of identifying risks and then managing or mitigating them so that their cumulative impact is as low as possible. That means ruthlessly removing all avoidable sources of risk and noise - so that the inherent risks of the market (changing customer demand, competitor behaviour, etc) can then be observed, responded to, and their associated opportunities exploited.
Self-generating Complexity
In response to the implementation barriers created by arbitrary service boundaries, delivery teams then typically attempt to work around them via the lowest friction route available. Rather than conducting a politically unpalatable root cause analysis and proposing a simplified approach that conflicts with the structure of the overall delivery program, it is easier to try using additional software and infrastructure complexity to address the problem. This results in an escalating feedback loop of bad design: not only is the architecture unnecessarily complex already, but additional complexity is then introduced to manage that complexity.
Unfortunately, the only way to break out of this loop is for some brave soul to put their hand up and conduct a “survival of the fittest” design cull, where every component of the architecture is ripped out and tested for critical system viability until what remains is the minimal skeleton actually required to deliver the baseline functionality.
Machine Learning as Universal Panacea
A more subtle variant of self-generating complexity relates to the application of machine learning itself. Given the relative immaturity and vast potential of the field of data science, there is now the additional lurking temptation to try using ML to work around any problem rather than analysing and solving its root cause. However, as Robert Frost said “the best way out is always through” – a phrase which captures the essence of how to avoid incurring crippling technical debt. Applied to data-driven product innovation, that means conducting patient and precise analysis to identify underlying causes of problems and solving them at source rather than building an ever-expanding shanty town of workarounds that is liable to catastrophic and terminal failure.
Effective Mitigation Strategies
What techniques can be employed to mitigate against these problems and create a reliable foundation on which to base your delivery? In our experience the two most valuable tools are a domain model and sets of BDD scenarios (or terse use cases) which describe the state and behaviour on which the anticipated business value depends:
Domain Model: this is a collaboratively defined conceptual model of the problem space shared between the subject matter experts and technical staff. Its key importance is that it explicitly names the entities of the business domain and their relationships to each other. In doing so, it creates a worldview and language that is shared by all stakeholders/members of the delivery team (a purposefully limited and relativistic scope, which is enough to ensure use cases can be fulfilled whilst avoiding the many pitfalls and dead-ends of enterprise data modelling). It is not a knowledge graph, ontology or database schema. Rather it is something which SMEs might express as a frequently iterated whiteboard diagram of labelled entities and connectors, and developers might describe using an ERD or high-level class diagram. This foundation is what allows code to be written in a way that precisely and unambiguously matches the collective intent of the team. Without it, you are building on quicksand.
BDD Scenarios: once a shared language has been established which describe the entities in the domain and how they relate to each other, the state transitions involved in the information flows and generated business value can then be captured (in practice this tends to be highly iterative, with new scenarios being sought that break the model and thereby drive its improvement). The emphasis here is not on automated testing capability – although that can be a very helpful by-product - but the communication of state transitions and workflows.
Once the workflows and information flows have been defined via which business value will be delivered, questions concerning the optimal deployment of human and machine agents can then be correctly and meaningfully addressed. At this point, it is then really important to return to the Strategic Alignment Model for one more pass. Newly equipped with a powerful model that clearly describes the state/data and behaviour of your domain, you can review each entity and function in turn to create an unambiguous and precise definition of what your market differentiators really are. Is it really the bespoke algorithm that your data scientists are working on, or is it in fact the data that the algorithm is outputting? If the latter case, is it really justifiable to keep investing in developing something in-house which ought to be (and will almost certainly end up eventually) a commodity purchase? These considerations will then be primary factors informing product roadmap planning – a subject beyond the scope of this post.
The result should be a system architecture that is the simplest thing possible to deliver the identified business value, and as a result is the cheapest to build, contains the minimum number of things that can go wrong, and is fastest to adapt to future market change.
