
Data Science is about building software
Earlier this month I was chatting with my old friend Pierluigi Casale (Data Scientist at TomTom, AI lecturer and researcher) about what seems to be the question of the century: "What is Data Science"? Tongue in cheek, I offered my very own answer: "Data Science is that thing you get when someone with a PhD plays with a Jupyter Notebook, and a technical architect refuses to let it anywhere near production because it doesn't have a single unit test".
Although sporting a PhD himself, Pierluigi agreed that my slightly caustic definition was indeed something he observed himself, and that he too was wary of. He mentioned how he often concludes the many talks he gives at conferences around the world with a diagram from the notorious paper "Hidden Technical Debt in Machine Learning Systems" by D. Scully et al.
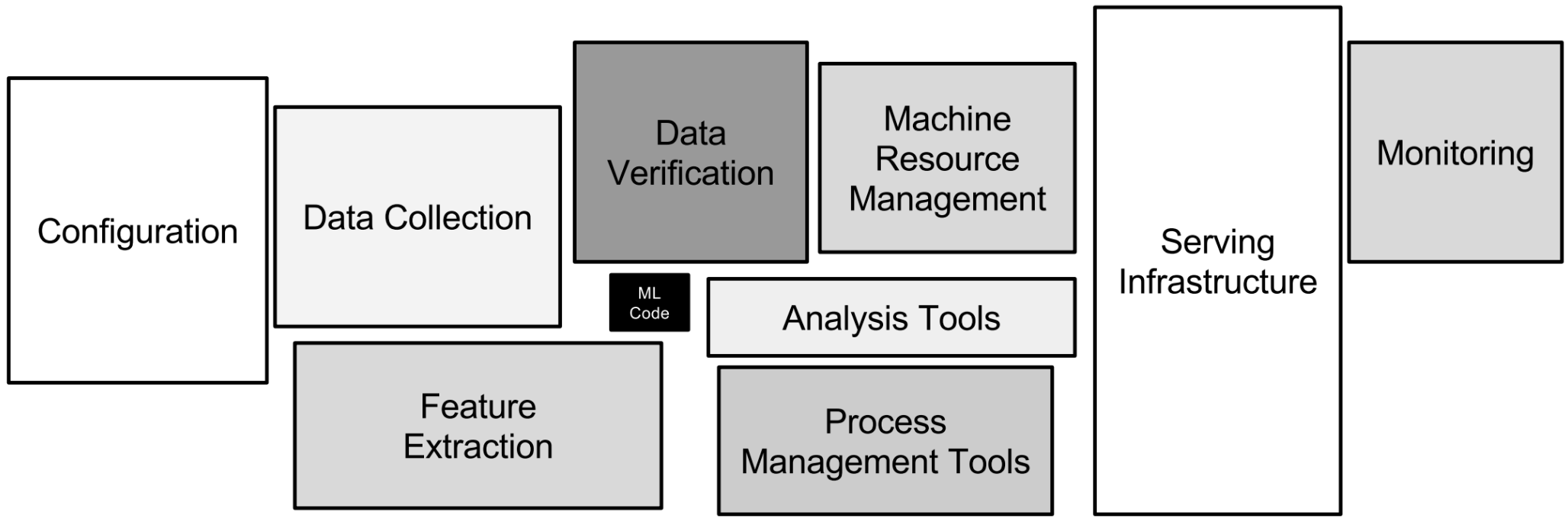
There is indeed a widespread assumption that Data Science and Machine Learning belong into a hazy limbo somewhere between data analysis, analytics, and R&D. Within this mystical space, a set of practices otherwise regarded as inefficient seem to be accepted as the norm: manual mining and manipulation of data; one-off transformations virtually impossible to replicate; casual scripting of code with total disregard of any development standard; artefacts laying around and code running here or there...
When Scully talks about "glue code" and "plumbing", he is pointing at the right problems but possibly underplaying the issue by being too humble about it. So forgive my bluntness and let me put that straight: Data Science is about building software.
Whether the context is academia or enterprise, research or commercial alike, the adoption of Software Development best practices, tools and methodologies is the key for efficient delivery of outcomes. At Data Language we have worked with a number of clients at different levels of "enlightenment", and witnessed first hand how injecting software craftsmanship into Data Science can lead to profoundly transformational effects. We can also testify how the development of our Tagmatic service has been indeed 10% Machine Learning and 90% software engineering: not much we could have done with our shiny model without things like containerisation, high availability, high throughput, load balancing, scaling, automation, security, governance, monitoring, and many others.
The adoption of established best practices in Software Development will boost productivity, shorten the feedback cycles, and produce more robust code that is easier to change, maintain, and ship.
Six things we at Data Language do and you should too
1. Ditch the darn notebooks
I'm fully aware this is highly controversial bordering sacrilegious for many, but the truth is these type of editors foster bad habits and are holding you back. They are like comfy, safe, cute trikes you got used to riding when you were three; but if you actually want to go somewhere other than your garden, you’ve got to move on and get yourself a bike.
At this year's JupyterCon in NY, the talk widely regarded as best of the lot was "I don't like notebooks." by Joel Grus. I wholeheartedly invite you to check it out.
2. Version control
A common refrain in favour of notebooks, is that they enable collaboration. Oddly enough, when further engaged on this topic and asked about which version control tool they use, what's their branching strategy, how often they merge, etc... it all unravels.
Collaboration is mighty important, so make sure you get on top of your version control strategy. (And ditch the darn notebooks)
3. Test automation and CI
Arguments for Test Driven Development and Continuous Integration are widely available and universally recognised as the single crucial factor that enables faster, safer, better code. The very same arguments apply to Data Science. The ability to move faster with your code enables quicker feedback and shorter iterations: you will be able to experiment and prove ideas quicker, boosting productivity. You will also end up with code that is designed better, and it can be transitioned into a production environment more easily.
4. Infrastructure as code
In order to take full advantage of the ongoing democratisation of computing power, it is crucial to write code that is portable and can be deployed wherever is faster to run it. In a typical development setting, we want be able to provision computing resources in the cloud, deploy our code there, execute it, collect outputs and dispose of the remote resources. And we want to be able to do this in a fully automated fashion, at the push of a button.
Many ways to skin this cat, but if I were to single out one thing you should do, and learn to do well, is containerisation. Plenty of great Docker learning resources around: get stuck in!
5. Data management
As in any other scientific setting, it is mighty important for experiments to be repeatable under the same conditions. We want to make sure immutability of inputs is preserved through transformations. Versioning and artefacts management tools play an invaluable role in the development of Data Science solutions. This goes hand in hand with practices discussed in points 2) and 3), and falls naturally from there.
6. Metadata management
Often the journey is just as valuable as the destination. As much as possible (and to the extent that is useful, of course!) we want to be able to retain key information about the process at hand, so that we can better interpret, analyse and enhance its outputs. The spectrum here is broad, from basic logging to systematic capturing and analysis of metadata. The point is: we want to be able to fulfil this function in the way that maximises the insights offered by the data being collected.
Metadata management is at the core of many activities that are either routine (eg compare performance of models), or required for production (eg backout strategy for a failing data pipeline), or further reaching into the realms of ethics and accountability (eg quantitative justification of a Machine Learning prediction). It is important we do it well.
Conclusions
I fully appreciate some of the recommendations above may feel daunting to the more traditional Data Scientists, due to such activities not (yet!) being typically associated with their profession. To some extent, we witnessed something similar in the past with network and infrastructure specialists, now evolved in DevOps that design and build infrastructure solutions through code, fully embedded in the fabric of development teams from the onset, sharing tools and methodologies.
Similarly, the key for enabling the evolution of Data Science from R&D practice to fully fledged enterprise function, lays in bringing data scientists and developers closer: before long the distinction will blur, and specialist knowledge will thrive on a common substrate of working practices.
At the end of the day, remember, Data Science is about building software.
