
Getting the most from your Sports Data
My name is Jim Howard and I am a freelance Product Manager specialising in developing products using data and content. After working at the BBC for a number of years, I have worked on projects for a number of clients including Government Digital Service, Eurosport and Stats Perform.
I got to know Data Language after working with some of the team on big publishing and audience-facing Sport products (World Cups, Olympics etc), when I was at the BBC and The Telegraph.
We have been discussing some of the issues that we have had to deal with over the years and the opportunities that are still there for companies to make more of the data that they consume. In this post, I will try and summarise some of the key areas we have identified and some areas that could still be developed further.
Sport, data and content in publishing
Now that the restrictions on Sport are gradually being eased, we thought it would be an opportunity to review some of the areas where Sport-related products have been developed and business issues have been addressed with a more innovative approach to the use of data (not analytics) as a core ‘building block’ to development.
As always in organisations, there are lots of great ideas around innovation but the business needs a focus - and sport is an ideal test subject. As we have found out, you can look at a major sporting event in isolation (Olympics, Football World Cup etc), review the outcomes, decide on what areas worked and then integrate into wider product development strategies.
I will try and break this down into areas that will be relevant to other products, not just Sport.
Buying in sports data
First off, you should look at refocusing Sport as a data proposition and not just a content one.
Most major publishers typically buy in fixtures, results and tables from a specialist sports data company. Users, and editorial teams expect that. Depending on the amount and scale of data, this contract is usually paid annually and is an ongoing cost. So how do you get maximum value from the data you are buying?
The data usually contains unique IDs for teams, players and competitions, as well as additional metadata such as dates, times, locations, rounds (semi-finals, round 13 etc) and venues. These data feeds also contain names of players, teams and competitions. A whole wealth of information that we could exploit much better than we were.
When we started looking in a lot more detail at the data that was being bought, you could start to see the opportunities to properly join the dots between the content proposition, the technical challenges, and what we wanted to build as a Product.
It wasn’t perfect the first time round we tried this, although we did get to the stage very quickly of having a process to tag content and create automated pages for all players, teams and groups at the 2010 World Cup.
We then realised that as Sport is so consistent, once you had a basic domain model in place, then you could approach development and products in a different way.
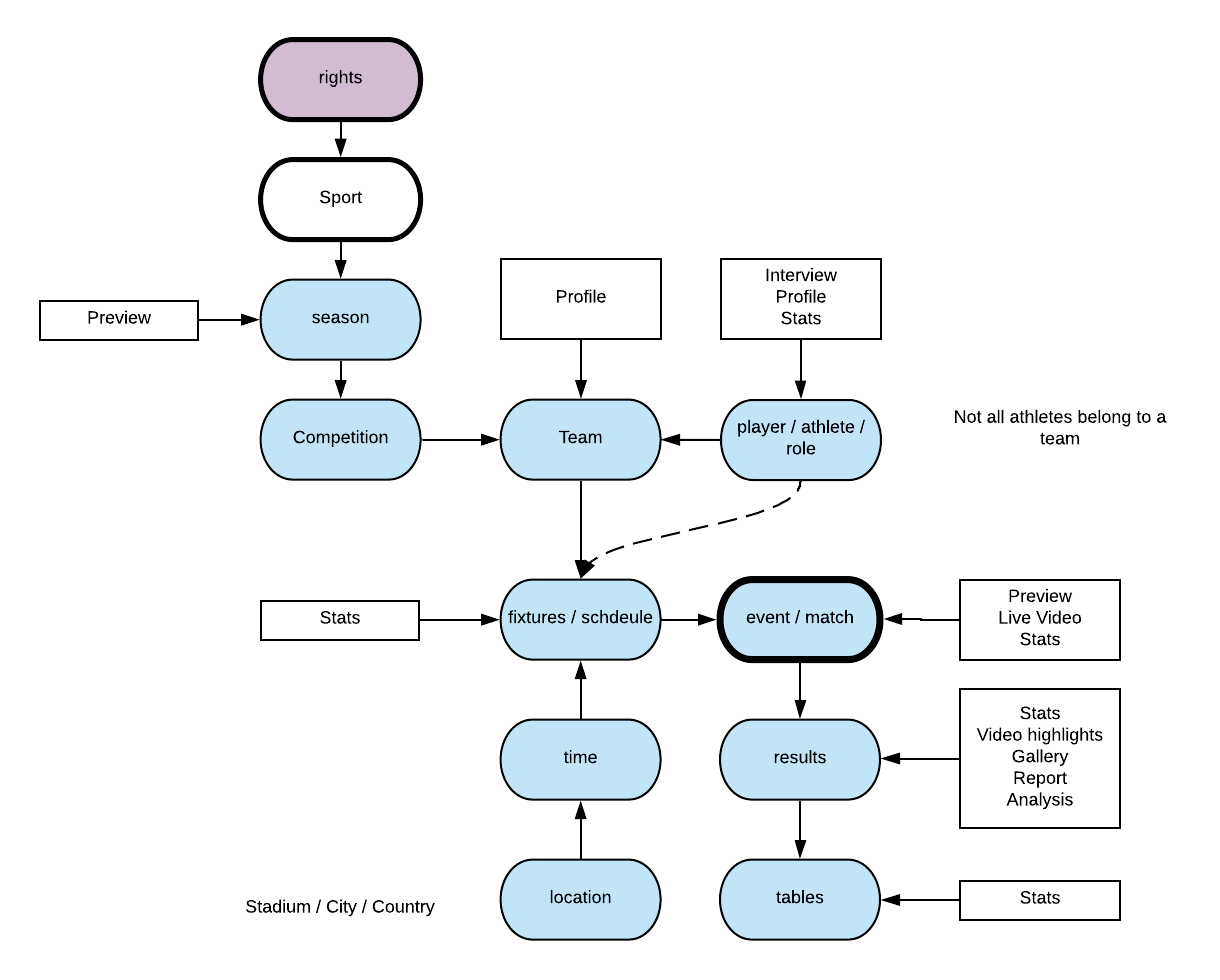
Using the data to help your tagging
Workflow is always a challenge, whether you are introducing a whole new system or just tweaking an existing one.
From a product perspective, I want consistent and accurately tagged content to avoid issues with SEO, duplication, URLs and historical inconsistency across different systems within a business.
Other business aspects to consider were ensuring we could align the editorial style guide, improving editorial team efficiency, enabling consistent reporting of traffic and ad revenue, allow for cleaner syndication of content and at times, manage tags in multiple languages (Bayern Munich and Bayern München are the same team), and managing alternate names and synonyms for your tags.
When we first introduced manual tagging of content, we had issues with consistency and accuracy. Even with guidance, individuals approached relevance and accuracy in slightly different ways.
Taking feedback from this, our next iteration was a semi-automated tagging process using NLP techniques, where we focussed tagging only on headlines and first 4 or 5 paragraphs of the content. The copy was cross referenced with the sport vocabulary we had created from the bought in data and tags suggested to journalists.
This created a much quicker and accurate workflow for the editorial teams.
There were unexpected challenges too, such as when a new CMS allowed creation of multiple tags by content teams, with no editorial oversight on tag quality. The CMS allowed audience-facing pages to be created automatically once a tag had been used several times - even if they were incorrect. This caused major issues for the editorial team, the SEO strategy and User Experience.
We revisited the key terms around sport that the data supplier had delivered, used that as a starting point for a controlled vocabulary for the editorial team, and then used machine intelligence to automatically retag the archive of existing articles, video and other content in the CMS, to ensure consistency.
Linking a content model and data
Another key part of this process is understanding the editorial workflow around fixtures and events and where a level of automation can help save time and effort.
There is a considerable amount of consistency around how events are approached within newsrooms, with editorial teams creating match previews, live coverage, reports, photo galleries, post-match analysis etc, all of which fit within a content model and data strategy approach. This thinking equally applies to video and audio, live and clips.
As part of a workflow review we could see that the editorial teams were taking time to manually create pages in the CMS in the days before a big weekend of sport.
We suggested using the bought in fixture list to drive automated creation of pages in the CMS for journalists. We identified what templates needed creating around a match - which links nicely with the content model work - and spun-up pre-tagged templates in the CMS when the fixtures were announced.
Before a match starts, we already know the teams, competition, venue, historical records etc. Depending on the sport, we will also know the athletes taking part in a match (football tends to announce starting line-ups about 45 mins before kick off) although other sports make announcements further in advance.
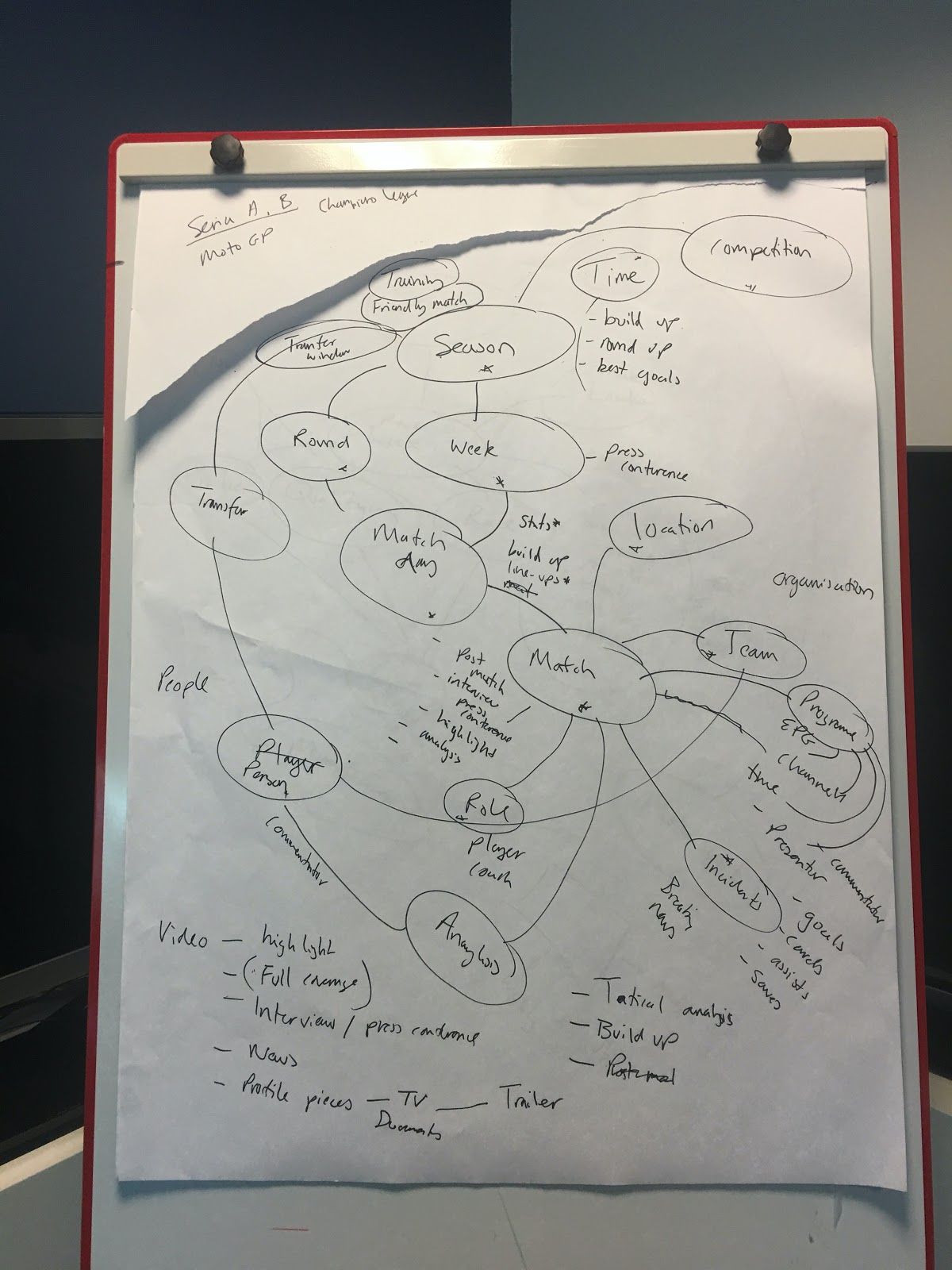
Scaling Up
This data-driven approach allows you to scale quickly. New competitions or events can be approached from a ‘we just need some new data’ perspective and this should fit with your ongoing data management strategy.
This is especially relevant around major events where you may want to cover new teams or events as part of the Olympics, Commonwealth Games or research has shown you that your audience wants more detailed club level NFL or NRL coverage.
If you want to create a new type of written content, such as a match report, that is an extension of your existing content model.
When you start adding in multiple media types used for coverage such as photographs and social media, you can begin to see where consistency of tagging and annotation is key to creating product propositions.
These methods can also be used for content gathering as well - from external suppliers to content supplied by correspondents and social media sources.
Data visualisation
One of the challenges every media business has, is how do you stand out from the crowd around Sport? Everyone has the same fixture list (that you have no control over) therefore a focus on the user experience and a unique proposition helps you stand out.
Depending on the amount of data that you are buying, there is a lot of mileage in offering a unique insight, and deeper analysis into the events or competition.
I worked on the Roboblogger project, part funded by the Google Digital News Innovation fund. We really dug into the details of what was in the football data that we bought and pushed the automated publishing of infographics as far as we could.
It helped that we had already put in place a controlled vocabulary of sport terms, which made the consistency between systems much easier.
We ensured that any graphics created fitted with the visual style guide of The Telegraph and were getting them published in under a few minutes after we received data about the events.
It’s not all about the website or app
Once you start digging into how a publishing business works, you can start to see how progress could be made by thinking about an ‘open data strategy’ within your organisation and allowing different systems to use the same vocabulary to make life easier, although that does start changing the business focus to manage data better - still a very overlooked area at the moment.
There are still multiple opportunities to join the data dots in businesses. Especially linking back end systems and archiving with audience facing products.
- Unlocking content archives. Always handy for Olympics, World Cups, and major events.
- Ensuring you can map multiple, external suppliers to a single tag or ID.
- Advertising and commercial consistency for teams and competitions and even individuals athletes.
- Providing consistency between content and tags after mergers between companies.
- Electronic Programme Guides (EPG).
- Video tagging - enhancing video with structured data - both your own video and inbound social media video
- Analysis and reporting.
Sport - or even an individual sport such as football - is a very consistent domain which makes it easier to integrate into your business model, or at the very least, look at Sport, as your first step towards utilising data and content in a structured and consistent way.
The M word
I have avoided writing metadata all the way through this so far.
Data suppliers provide very consistent products and can help you solve some business and product issues. Linking together data and content to create better products both for internal processes and audience-facing or syndication purposes.
For example, you shouldn't have to rely on editorial teams to rebuild a section or feature. We can do this based on the data we have. If google enables a new rich snippet type we can add this markup etc.
Most media organisations buy in content feeds, and although the assets are tagged, they won’t be quite the same as the vocabulary that you use within your organisation. Clarifying that vocabulary will save time and money between systems and your own team.
The key to structured data is a well structured content model, a data management strategy and metadata.
If you want to extend the model, then you can have a list of your contributors and journalists as well. This would enable me to create a feed or even a subscription based-product based on a question such as:
“Give me all match reports (content type) written by Joe Bloggs (Author) about Melchester Rovers (team) in the past 6 months (date range)”
Are you making the most of your bought data and content?
Data management is a challenge and unfortunately it does tend to get lumped in with data science and analytics within a business.
I prefer to look at the reference data as a core building block for the Product. I want to look at the details of the data contract to see what is being bought. Does it fit with the current editorial strategy or is it just a historical add on? Is this what the audience is looking for or expecting? Do they come to your site or buy your paper for a specific type of coverage?
The cost of the data contract varies from company to company and of course also depends on the amount of data bought. One thing in my experience that is consistent though, is that usually only a small amount of the data is being used by the business.
The coronavirus pandemic has caused a raft of fixture cancellations, rearrangements, postponements and economic challenges across the board for industries associated with sport.
Meeting new business challenges is going to be about agility and speed of response to new opportunities.
Companies will have to be more agile in the future and the key to this agility is having scalable and well marked up content that can be repurposed.
The future
Hopefully 2021 will be a big year for Sport with a still to be defined weekly sporting calendar, a rescheduled Olympics in Japan, a rescheduled European football championships, a Lions Tour to South Africa and lots more.
Companies will want to make the most of these opportunities for engaging audiences and hopefully these examples can start some processes we have been involved in:
- Advertising and commercial consistency - for teams and competitions and even individual athletes
- Unlocking under utilised content archives
- Providing consistency across content and data after mergers between organisations
- Electronic programme guides - a key syndication product and internal tool for some organisations
- Video clips and live coverage
Around major events, other departments within your organisation that don’t usually do sport coverage, may well want to start creating content about the event such as documentaries etc that you may want to leverage.
Many of these ideas are not just relevant to Sport, the patterns I describe can be applied to many domains and publishing any form of content, whether that is in news, sport, entertainment, healthcare, science, or finance. Adding geospatial metadata into the mix adds another dimension, and more avenues for adding value.
Every domain has its own challenges but Sport is a very nice place to start. If you would like to know more, please do get in touch.
