
GraphQL and Graph Databases
5 latin characters
Until recently, my understanding was that apart from 5 latin characters GraphQL has got little or nothing to do with Graph Databases. But things are changing, Graph Database vendors have started bringing these two technologies together. A recent project has given me some insights.
For some background, GraphQL is a contemporary API interface standard used as an alternative to REST. GraphQL was originally developed by Facebook. It provides a structured query language for querying (and mutating) data, along with a runtime implementation to invoke those queries upon your data. In pretty much all implementations it uses JSON as its serialization format.
REST (I suspect most readers know this) is a lightweight low-level API standard for performing uniform and a predefined set of stateless operations on data aligned with the HTTP verbs. With REST you have to design and build your API interface contract for that set of operations - and while of course there are common patterns in REST APIs, this is very much arbitrary. REST makes no assumptions about the high level API contract or the underlying data model. The developer defines both. With GraphQL you only define the data model (the GraphQL schema), exposing to the GraphQL runtime and your consumers what the shape of the data is.
With a GraphQL query you can request only the minimum data required to fulfil your current need. Of course you can do this with a REST API too - in fact it is a common pattern with JSON REST APIs to filter response data by JSON fields using dot notation. But of course you need to build this yourself.
GraphQL does a lot more for you to boot, as well as out of the box query patterns for mutating data, it also supports subscriptions (pub/sub style) - so your GraphQL client can subscribe to server side events, and have data pushed to it.
The developer ecosystem around GraphQL is superb now - The Apollo GraphQL implementation works beautifully with React - integrating with React Hooks for query and subscriptions. Apollo also has in-browser developer tools akin to the redux-devtools for GraphQL debugging, and you can manage local app state via Apollo using the GraphQL schemas / queries etc.
Caching and performance
Requests to GraphQL are typically all POST requests - not great for caching you ask ? Indeed, this is where REST has excelled for years. But the GraphQL server implementations have come to the rescue. The Apollo GraphQL server has an internal caching layer that supports full response caching, and fine grained field-level caching (read more here )
Amazon’s AWS AppSync is a fully managed GraphQL service built upon the Apollo technologies - and can source data out of the box from other services such as DynamoDB, ElasticSearch, REST APIs etc. With fully managed caching and real-time data subscriptions, it really does make your developer life easy.
On the surface it still appears GraphQL has little to do with Graph Databases. Yet increasingly we are hearing about how they should go together like bread and butter, sausage and mash.
Not all graph databases are equal
I won't go into depth about what a Graph Database is, but am going to explore some of the options available, and the relationship between Graph Databases and GraphQL.
Graph databases come in several flavour combinations. First up you have RDF graphs vs Labelled-Property graphs. The first big choice. Both are very different. Your primary use case is important here. Essentially if you primarily need to walk, query and analyse paths through your graph, then Labelled-Property graphs are probably the way to go. If you are more interested in the nature of the relationships between things, and creating rich semantic representations of things, then RDF graphs hit the spot. Both types have their own well-developed query language. Labelled-Property graphs are typically queried with Cypher or Gremlin (eg Neo4J), RDF graphs are queried with SPARQL.
While most mainstream RDF based graph databases are fully compliant to the RDF and SPARQL W3C standards, not all RDF graph databases are equal. Each has its own implementation nuances and come with their own added extras (decisions, decisions!):
- An RDF graph database may or may not support reasoning (to some degree of the RDFS and OWL standards).
- Reasoning may be at query time (backward chaining) or at write-time (forward-chaining).
- The way reasoning is implemented can dramatically impact performance.
- Add-ons and extensions for GeoSPARQL, Path analysis, Full text search, connections to other datastores etc.
To give some examples (DISCLAIMER - apols to those vendors not mentioned, I am only referencing those I have worked with properly hands-on, and this is not an exhaustive features list - it’s just a flavour) :
GraphDB (Ontotext)
- Fully compliant with RDF/SPARQL standard;
- Highly compliant and configurable OWL / RDFS forward-chaining reasoning (materialises inferred knowledge at write time);
- Unparallelled full-text-search capability using lucene, or via bi-drectional connectors to external SOLR or ElasticSearch clusters.
- Ability to materialise post-inference fully structured JSON or JSON-LD objects into ElasticSearch indices or MongoDB
- Geospatial querying and other extensions..
- Rich visual query and management workbench UI
- UPDATED May 2022 - Path query capability is now avaialble using a SPARQL extension plugin
Neptune (Amazon AWS)
- Fully compliant with RDF/SPARQL standards;
- No reasoning capability
- Fully managed cloud service
- Highly, highly horizontally scalable (primarily due to lack of reasoning)
- Full text search capability via connector to ElasticSearch - materialisation into elastic is constrained (you cannot materialise user-modelled JSON objects into an elastic index), but delivers good full-text search utility.
- You use this either as a Labelled-Property graph (using Gremlin) or an RDF graph (with SPARQL)
- No query workbench/admin UI - you need to install your own
- Fully compliant with RDF/SPARQL standards;
- Highly compliant and configurable OWL / RDFS backward-chaining reasoning (materialises inferred knowledge at query time);
- Extremely fast online write times (due to backward-chaining model)
- Adequate full-text-search capability using internal indexing
- An outstanding SPARQL extension for PATH analysis (Pathfinder) - you can query for paths, shortest paths with weighted edges, normally only possible with labelled-property graphs
- Geospatial querying and other extensions..
- Rich visual query and management workbench UI
So you can see that each of these three are fully W3C compliant RDF / SPARQL graph databases. But each has one or more killer features, that the others do not.
GraphDB - the post-inference connectors to ElasticSearch and MongoDB unlock some outstanding technical and data architecture patterns out of the box - UPDATED May 2022 - GraphDB now also has comprehensive Path query capability using sparql extension plugin
Stardog - combines the semantics of RDF with sophisticated Path querying and analysis.
Neptune - fully managed cloud service with unparalleled horizontal scalability, but no reasoning.
The upshot - choose wisely based on your requirements now, and what is likely to matter most in the medium term.
..and then enter stage right, GraphQL
Sausage and Mash or Pineapple on Pizza ?
How do GraphQL and Graph Databases fit together? As we learned earlier, GraphQL is a REST API alternative with a structured query language combined with a runtime for query processing and serving data to GraphQL clients (and it is almost always implemented with JSON in mind).
So why are Graph Database vendors getting involved and what do you get for your money?
The cynical marketer in me says those 5 latin characters definitely count for something. Which sales manager wouldn’t love the potential energy pressure in the ready-to-explode singularity of Graph Databases and GraphQL (while humming ‘Don’t stop me now’).
However, GraphQL does only provide another query mechanism for your graph database alongside SPARQL or Gremlin. Moreover it is much less expressive, and most definitely not designed for exploiting the rich semantics of RDF and OWL.
In fact if you go all in on a michelin-starred Graph Database, and only use GraphQL to query it, I would argue you really probably don’t need a Graph Database - a NOSQL JSON store would probably suffice. Of course, if you have forward-chaining inference in your graph database (as with GraphDB), then your GraphQL queries will benefit from the RDFS/OWL semantics you have modelled your data with, which does add weight to the value-proposition.
Still hungry ?
Ontologies are an important part of the picture. In the RDF world an ontology semantically describes the model and nature of your domain, and ultimately the data structures stored in your knowledge graphs, and if inference-aware, they describe the meaning of the data, and how we reason upon it. Typically these models are communicated up and down our tech stack (and the responsible developers), and often all the way out to consumers of your APIs (public or enterprise-internal). While we typically move data around using JSON the linked-data aficionados will know well that if we do this using JSON-LD, we can use the same ontology models from the knowledge graph (or a subset) for describing the JSON-LD payloads we ship around outside of our graph database.
So do we need GraphQL to take advantage of these ontological graph models ?. No we don’t, we can do it with normal REST APIs (querying our graph with SPARQL) and using JSON-LD payloads - but of course we have to build more API code to do this.
With GraphQL though we can (we must) formally describe our data structures as GraphQL schemas, and so we have a great opportunity here to align our GraphQL schemas with those same ontology models that describe the data in our knowledge graph - this could be either a subset of our ontology landscape, or possibly the superset, if we are using other GraphQL (served) data sources aside from the data in the graph database. This is starting to look like very nice decoupled data architecture with well structured cohesive data models, with possibly the most efficient mechanism for consuming data in our web/mobile applications (a GraphQL client).
It is looking more tasty
Adding GraphQL client interfaces to a Graph Database does make life easier - if you are rapidly prototyping straight from the graph, or federating data into an external GraphQL server there is a nice pattern for making a common set of well described data models.
The Graph Database vendors have indeed jumped on-board the GraphQL sushi train (and it’s not all about those 5 latin characters). Stardog and GraphDB (from Ontotext) both offer GraphQL clients now.
At this point I was going to show an example of how GraphQL might be used to query a Graph Database, but Jem Rayfield at Ontotext has already done the job in his superb Star Wars blog post (if you have got this far, then this is a must read).
Ontotext has taken the next logical step and created a ‘Semantic Object Service’ that automatically generates GraphQL schemas bound to the underlying RDF data model in GraphDB, moving us towards the ontology ubiquity I described above, where your domain ontologies are expressed in the knowledge graph, and across your wider data-estate, including your GraphQL schemas. Nice work.
Jem concludes by saying :
GraphQL is a very popular graph query language, well used, known and liked by developers. The Ontotext Platform uses GraphQL to lower the barrier of entry to knowledge graph data, whilst still providing the full expressivity and power of SPARQL.
and this is a key message, which equally applies to Stardog and any other graph database that may yet offer a GraphQL client. While GraphQL lowers the barrier to entry, GraphQL gives you only as much as it is able to with respect to querying and graph traversal; to really unlock the power of the graph database, you will need to use SPARQL.
But if you never plan to, and you are not interested in reasoning either, then possibly you should ask yourself if you really need a graph database ?
What if you want to use GraphQL as the primary API technology in your stack, but want to use SPARQL too to access the graph database (amongst other tech)?
A mixed data technology case study
In a very recent engagement, the Data Language team have been working on a Smart Cities IoT project. The nature of the domain meant the type of data we needed to deal with was very ‘graphy’ in nature, and the ability to describe our data semantically and traverse a graph with SPARQL was of high utility. Inference was less of a concern. The proof of concept for the project was brought together in AWS with :
- AWS MSK - a high performance Kafka message bus to consume, orchestrate, and distribute IoT sensor events
- AWS Neptune to give us our scalable RDF based smart city knowledge graph
- A set of JSON-LD REST API endpoints invoking SPARQL queries on the graph running in Kubernetes (EKS)
- A suite of Kafka event processor consumers and producers deployed into Kubernetes mutating the graph, and emitting new events based on our business logic rules.
- AWS AppSync - the GraphQL engine sourcing events and the JSON-LD REST APIs from Neptune, providing the primary developer interface to our client applications
- A ReactJS built UI using GraphQL react-hooks to subscribe to real time events data, and to query data from the sensors and our knowledge graph (ultimately via expressive SPARQL queries).
A simplified view of the architecture looks essentially like this :
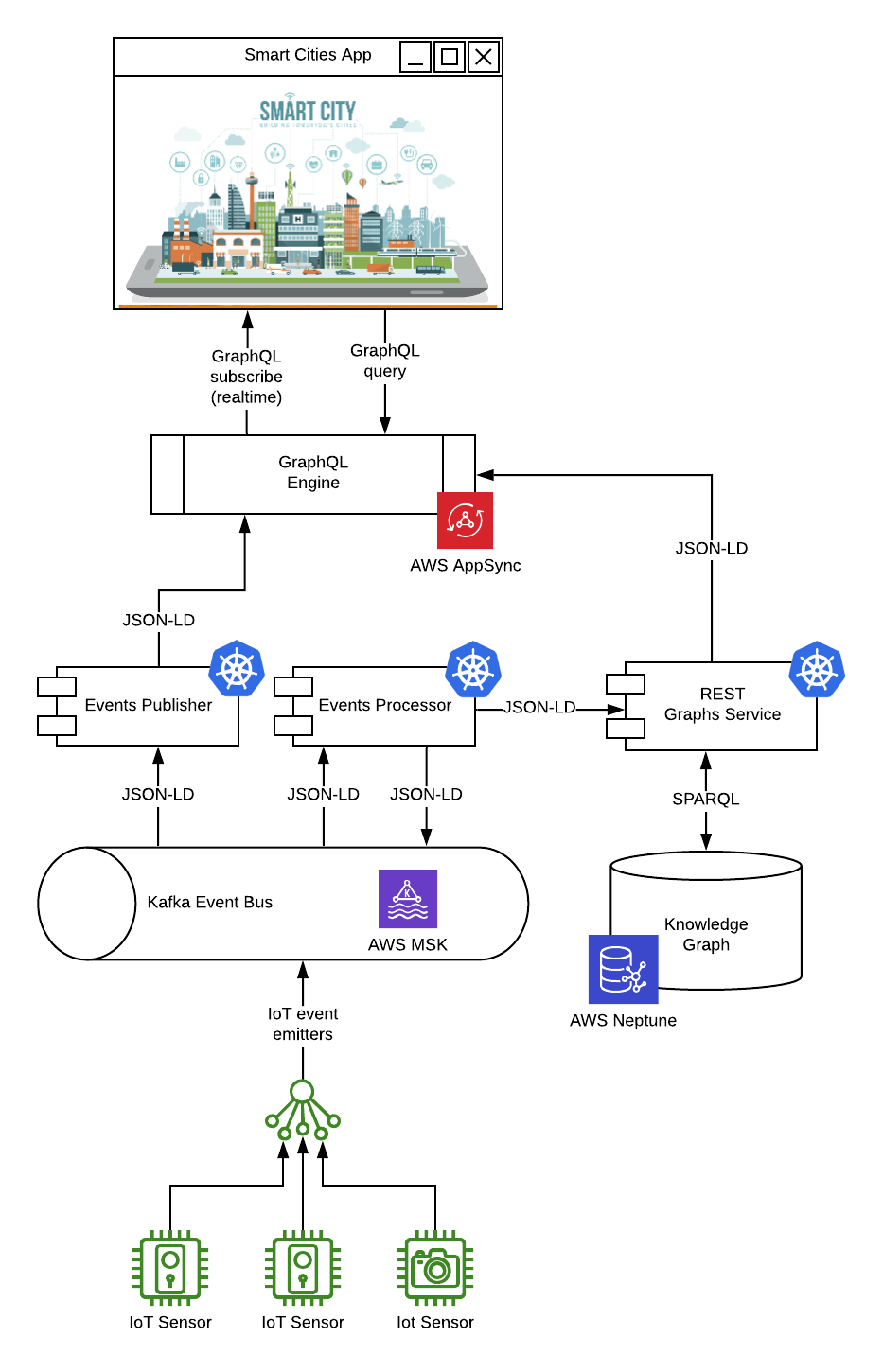
The kicker was modeling data across the entire stack using a suite of ontologies. These ontology models describe our knowledge graph data, our IoT message payloads in JSON-LD and were all federated in the primary application API expressed as GraphQL schemas in AppSync. Building the ReactJS front end using the Apollo GraphQL client and react-hooks was a very nice developer experience.
Dessert
While GraphQL technically has little to do with Graph Databases, they are not a perfect match like sausages and mash, GraphQL is just another API / query technology, and not as expressive as the native graph database query languages like SPARQL, but in itself is a high-utlity, very sweet technology.
There are some clear synergies, and do provide some of that warm comfort food feeling when used together. GraphQL does give you an easily understood and very developer friendly way into a graph database. Once you add the secret sauce of domain ontologies describing both your knowledge graph and possibly even your entire data-estate, expressed through your GraphQL schemas, then you have a very nice pattern for a decoupled data architecture with well structured, nicely communicated data models across your technology stack, and out to your consumers too - making for efficient application development using the GraphQL ecosystem. Get stuck in.
