
Resource Identity and httpRange-14
I recently finished up a lead architect engagement on a very large semantic publishing implementation for a finance client in the City of London. Digging out some old notes, I noticed that the delivery has been bookended by reflections on the pain caused by httpRange-14.
This problem has been debated amongst some very smart people for ten years plus now without any generally accepted solution being forthcoming, and more recently I have begun wondering whether the real issue is more a function of the question itself. So as an experiment, at the start of the program I tried to take a step back to see if a different perspective might add some clarity. In doing so, I decided to revisit a book that I last read many years ago, Saul Kripke’s seminal text Naming and Necessity.
The end result was a draft blog post I wrote early last year that somewhat optimistically finished with the sentence “It will be interesting to see if there are any obvious flaws I have overlooked, and what challenges are thrown up once we proceed to prototyping the solution.” It prompted a lot of interesting internal discussion at Datalanguage but in the end we decided not to publish because, as Paul pointed out, the use of blank nodes on which the proposal depended is problematic for a number of reasons.
The follow-up I wrote a couple of weeks ago, and it is set out below. It evolved out of my client handover notes on URI strategy but quickly turned into another discussion about httpRange-14. Somewhat encouragingly there has been clear progression in my thoughts particularly with regard to URI binding and httpRange-14 itself, about which I’ve now reached some concrete conclusions which seem both coherent and practically viable.
Resource Identity and httpRange-14
As practitioners of Domain Driven Design, one of the early steps we perform in the modelling of any new domain is the classification of its resources into entity types and value types. This is a question of identity and context:
- Value types are types which are best modelled as data: their “identity” is determined by their attributes (and for this reason, in code they are generally implemented as immutable). An example might be Postcode: in most contexts, changing the string value of a postcode simply means you have a new postcode.
- Conversely, Entity types have an identity beyond their total set of attributes. An example might be Person, where - in most contexts, at least - it makes sense to model someone as the same person regardless of which attributes might change over time (for which reason, a domain where it could conceivably make sense to model Postcode as an entity type is workflow management of postcode creation and allocation).
This has an impact on URI strategy. Entity types typically require synthetic/machine identifiers such as GUIDs, Twitter snowflake IDs or similar, whereas value types will normally use the text or hash value of their identity-conferring attributes. So in the examples from Jeni Tennision’s discussion of Opaque URIs:
http://id.example.org/house/NG9_3HZ/4
http://id.example.org/house/0aef0218
A domain driven design practitioner might agree that whilst the former has advantages in terms of hackability, it should only be used in addressing contexts. If your domain resource is really encapsulating the identity of physical buildings then you should adopt the latter strategy. That way, your design will be resilient to high impact edge cases such as house numbers or postcodes being reallocated. In short,
when designing URIs, start by analysing resource identity. Once you understand the > nature of the nodes in your graph, you can implement resource identification with > some degree of confidence and then move onto modelling the arcs.
Putting this into practice, a helpful way of resisting the urge to jump straight into traversing the graph is to start by modelling your domain using ERD techniques and only switch into linked data graphical modelling once you’ve nailed your URI strategy.
As regards URI structure, a strictly minimalist policy has a lot to commend it. In this respect URIs are like code: the less it takes to achieve your goal, the higher the likelihood of good design and the less there is to go wrong. “If in doubt, leave it out” definitely applies, and it is then generally worth testing your confidence in everything that remains as well. The result is normally something that looks a lot like:
http{s?}://{authority}/{uid}
where
{uid} = {namespace?}{id}
and
{namespace} = the minimal virtual path prefix required to ensure uniqueness within the authority's hostname/port naming scope
For synthetic identifiers a namespace is rarely required, apart from the case of incremental integers which should normally be avoided for other issues relating to distributed synchronisation. In the instance where a namespace is necessary, then the chosen virtual path should either be meaningless or else an intrinsic and version-independent attribute of the resource, such as type alias/label. The latter is not an entailed requirement for opaque URIs, but on purely aesthetic grounds it still seems deeply ugly to me to have URLs such as the above dereference to things which aren’t in fact representations of houses.
One of the more interesting consequences of this view of resource identity relates to how reference is assigned. If resource identity is not a function of attribute values, then clearly identification (i.e. what a URI refers to) can’t be determined by attribute or property matching. The main alternative model of reference determination was set out by Kripke in Naming and Necessity whereby proper names act as rigid designators the denotation of which is set by a one-off “baptism event” at the point of creation/adoption within a social group. By way of summary for those unfamiliar with the work, Kripke proposes something of a return to John Stuart Mill in taking on the previously dominant descriptive theories of naming that had been advocated by Bertrand Russell and Gottlob Frege amongst others (interestingly, the distinction between sense and content that Jeni Tennison makes in her post about punning and httpRange-14 has echoes of Frege). Kripke objects to descriptive theories of naming on the grounds that giving meaning and fixing reference are not the same thing. Instead, Mill’s position that names have “denotation but not connotation” - which seems an excellent description of opaque URIs - is developed into the notion of names as rigid designators, which are effectively opaque identifiers whose references are bound at the point of social adoption.
Such a viewpoint seems consistent with experience. URIs refer to resources because social groups (i.e. those performing the URI authority function) decide they refer to those resources: where those URIs are URLs, that is reinforced by the behaviour of DNS resolvers, but in the instance that a URL temporarily dereferences to a wifi login prompt that doesn’t signify a change in meaning. Isn’t this a contradiction of the notion that URLs are late bound? No, because the thing they late-bind to is representation, not the resource/conceptual mapping - which is in fact early bound by the authority for that URI at point of creation. What about the late binding enforced by the constraint on using hypermedia as the engine of application state? Again no contradiction, as that concerns late binding of client to URI rather than resource identifier to concept:
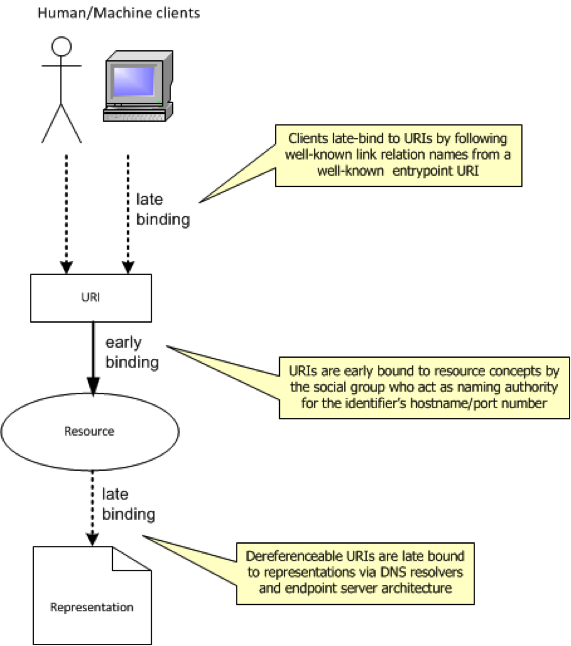
The notion of resource identity also has important implications in one other area. For the last couple of weeks I’ve been conducting a technical retrospective and handover to the client’s architecture team on one of the largest semantic publishing implementations in the UK right now. Part of this has been a review of URI strategy and the decisions made around httpRange-14 (or httpRedirections-57 as it has become) . Due to previous experiences of the pain entailed in coding clients against fragment identifier URIs (namely: the ambiguities introduced about whether a given fragment identifier denotes a document fragment or an NRI; the problems certain HTTP request processing frameworks have with fragment identifiers; the lack of portability to other better solutions that might be devised in future), this time we chose to adopt the 303 strategy. In doing so, we avoided the ambiguities and additional programming complexities but at the expense of performance due to all the additional, and worse uncacheable (a bug in the RFC now being addressed as part of httpBis) 303 roundtrips. For something that seemingly generates no business value to most customers - i.e. anyone who doesn’t have concrete use cases which depend on a formal distinction between information resources and non-information resources being maintained - both strategies are definitely a very long way from ideal.
In preparation for the technical retrospective sessions and having now been bitten by both approaches, I took the opportunity to revisit the recommendations with a more critical perspective. In doing so, I arrived at the realisation that there are actually multiple interpretations of the term “resource” in use within the web community right now. I decided to swap a domain-driven approach for a constraint-driven approach - the constraint in question being that I’m not using either 303s or fragment identifiers any more because they both suck :-) - to see if any of those interpretations offered an alternative way of thinking about the domain which a.) avoids the problem and b.) is consistent with the way the web works right now. The use of domain modelling was limited to prioritising the analysis of those interpretations: by starting from the interpretation of “resource” which most closely models how language and identity works in the real world, then there was a good chance that the hard part of actually solving the problem could effectively be left to Natural Selection meaning scope would be limited to modelling only:
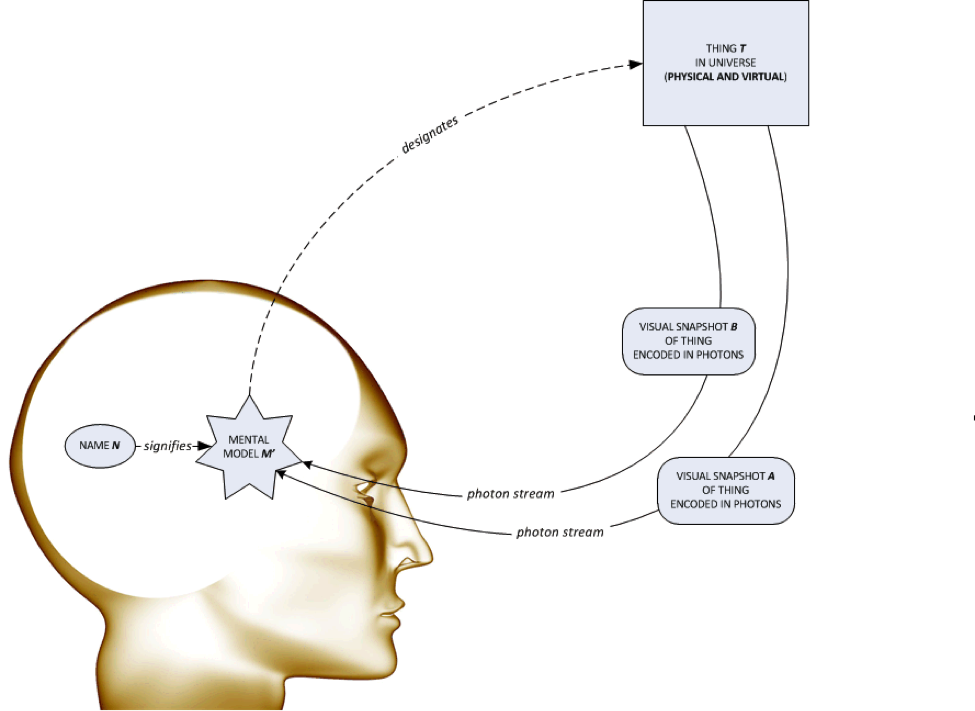
The diagram above describes how we assign identity as we perceive the world. Our retinas detect a continual, undifferentiated stream of photons reflected from the environment around us, which we then filter and interpret using mental models or templates. For example, I have a mental concept of my cat, and that allows to me to assign continuity of identity to any photon stream (e.g. cat in kitchen, cat climbing tree) which I can map to that concept. When I assign a name to that model, participate in a social group and there is enough commonality between our named mental models, then language becomes possible:
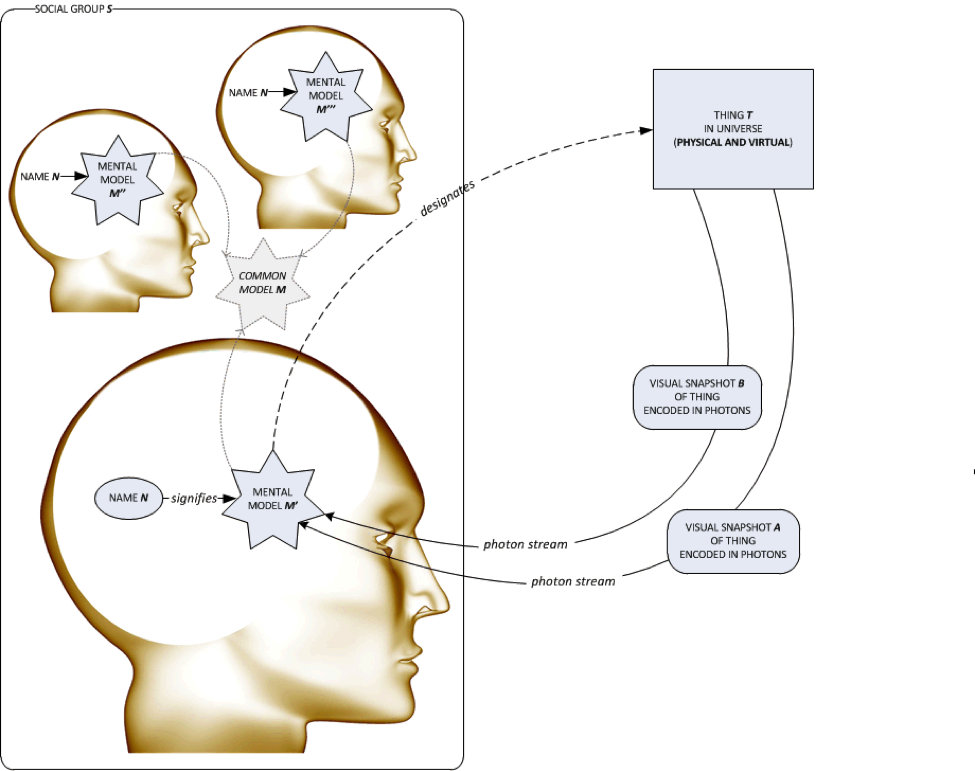
Now let’s extend the first diagram to include mediated perception:
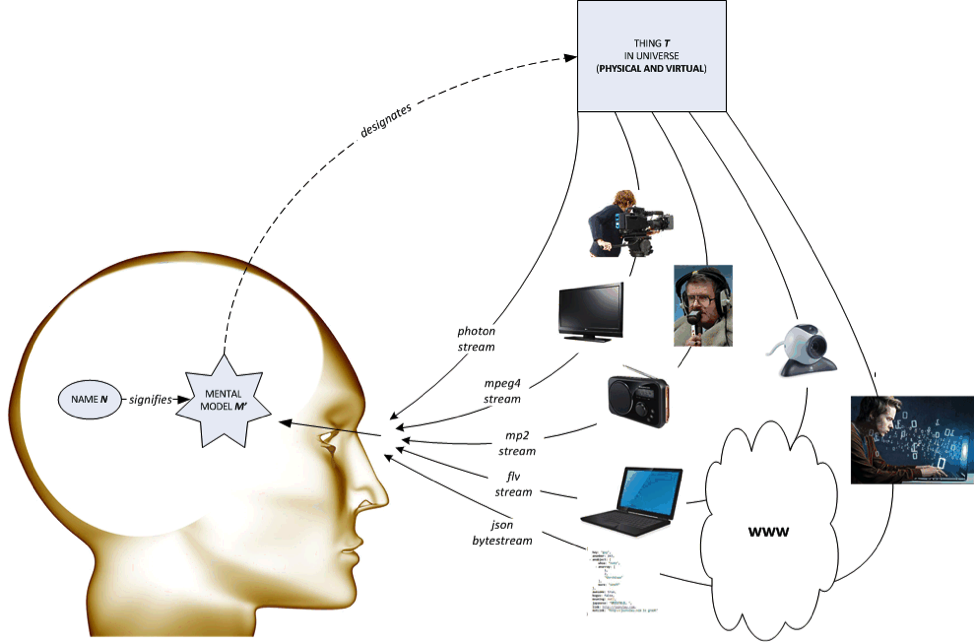
This shows a sliding scale - from direct perception, live MPEG4 video broadcast, MP2 accessible audio description, web Flash streaming to web-published text – of different formats in which the essential information content of the same real world entity is encoded. Translating the web examples into the terminology of HTTP, the name N is a URI, the mental model M’ is a resource and the encoded information formats are representations. This corresponds very encouragingly to the definition of resource as defined in section 1.1 of the older URI spec RFC 2982 (which has unfortunately been superseded by the open, and arguably less helpful, definition in RFC 3986: the term “resource” is used in a general sense for whatever might be identified by a URI):
A resource can be anything that has identity… Not all resources are network ”retrievable”; e.g., human beings, corporations, and bound books in a library can also be considered resources. The resource is the conceptual mapping to an entity.
This interpretation of the term resource I’m going to label concept-centric.
In contrast, the interpretation of resource implied by the Cool URIs recommendation I’m going to refer to as document-centric: although section 2.1 describes the distinction between resource and representation and its consequences in relation to content negotiation, it is apparent from the diagram in the first part of section 3 that each document has its own URI and is therefore a resource. In section 3.1 this is then expanded into the requirement for either 303s or fragment identifiers, on the basis that any real world “Non-Information Resource” needs a corresponding web document “Information Resource” which describes it:
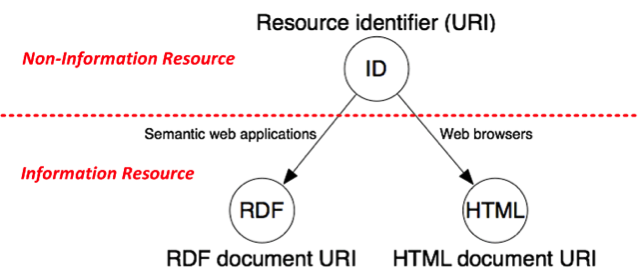
The concept-centric interpretation views the distinction between Non-Information and Information Resource differently, and of essentially no value as both variants are functionally identical:
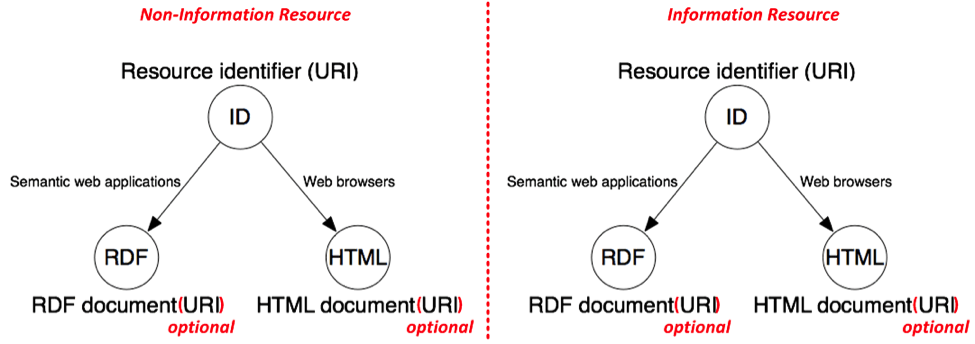
This view says that RDF and HTML documents are representations, not resources. They only need URIs in the instance that the separate concept of the representation’s byte stream is also required. In such cases a Content-Location header should be exposed with the URI for that concept. On the other hand, a description of a real-world entity is a resource, because a description of something is conceptually different to the thing itself. The description’s URI should simply dereference to some kind of representation in exactly the same way as a URI for a real-world resource. For example, URIs denoting a.) London and b.) a description of London, just work as follows:
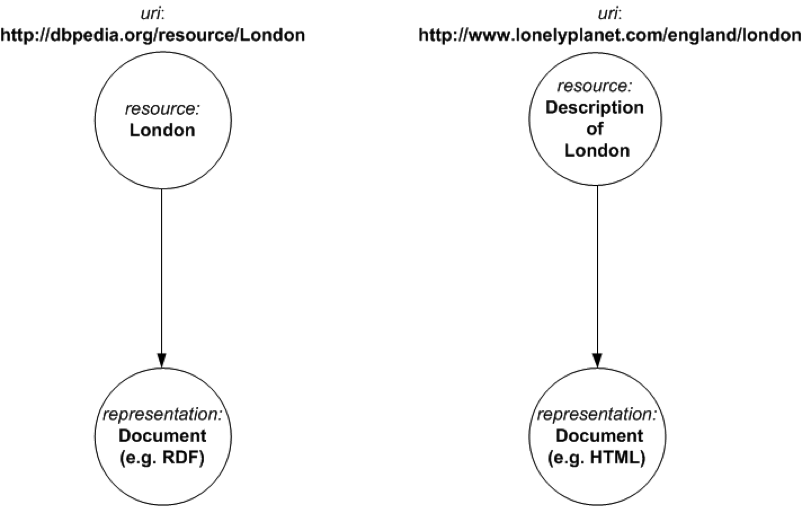
So, adopting a concept-centric rather than document-centric interpretation of “resource” has the following consequences:
- URIs are late binding in all aspects except denotation: what a URI refers to is determined at creation time by its naming authority rather than at runtime via a dereferenced representation.
- As with new terms introduced into natural language, ambiguities or misunderstandings that arise in the early adoption of a newly published URI should be resolved via recourse to the publishing social group – i.e. the URI’s naming authority.
- There is no non-trivial difference between an Information Resource and a Non-Information Resource: URIs simply denote concepts in the real or imaginary universe, and optionally derefence to one or more informationally equivalent representations.
- A representation is not a description: a representation is a byte stream whereas a description of a resource a distinct concept in its own right.
- A URI which denotes a representation (i.e. via a Content Location header) denotes the concept of a byte stream , not the byte stream itself.
- 303 response codes should be used solely for standard See Other semantics.
- Fragment identifiers should be used solely to denote resource parts.
- No change is required from how the web works right now.
In other words by slightly changing our perspective on the problem, it essentially disappears.
What about the scenarios where a naming authority has not published any/adequate information to allow URI consumers to disambiguate denotation to the extent required for the consumers’ use cases? Simple: in the absence of any better alternatives, consumers should mint their own unambiguous URIs that do meet their needs. My guess is that this will only be an issue for a few naming authorities anyway: either those participating in the linked data cloud who are currently larger enough to be used for general purposes (e.g. dbpedia, musicbrainz, etc) or else those organisations which have strategically targeted niche verticals where they perceive there to be longer term commercial advantages from owning the dominant vocabulary. It seems reasonable to request of such organisations that in order to realise their goals they conform to a more formal definition of resource that is consistent with the demands of semantic reasoners.
In addition to the clear pragmatic benefits of adopting a concept-centric notion of resource, I then discovered that such a position also seems to be consistent with the views of one of the main authors of HTTP. That finally sold me on the viewpoint. In a typically entertaining and strong post from Roy Fielding to the TAG mailing list dating back to 2002 - worth a full read - he makes the following comments:
Resources are not transferred, just as identity within the real world
is not transferred when it is accessed. That doesn't stop us from
reasoning about rocks, plants, chairs, or my dog. In fact, the
separation of identity from representations of an identity is
necessary to reason about them at all. That does not mean that the
resource and the representation are both identified by the same URI;
they are not the same resource. It means that you can reason about
resources and reason about representations of resources, even if you
don't know "the most appropriate URI" that does identify the
representation as a separate resource.
In short, the only reason this gives anyone in RDF land heartburn is
simply because their definition of resource doesn't match that of the
Web, or that of reality.
I absolutely refuse to consider RDF as a useful technology or the
Semantic Web as the future of human communication if its reasoning
power is incapable of describing one of the fundamental facts of life,
particularly since the only reason it is incapable of doing so is
because a few people suffer from the unfortunate belief that it is
easier to change the Web than it is to change their preconception
of what it means to be a resource in RDF. Change that preconception
and RDF becomes capable of reasoning about both resources and
the representations of resources through one level of indirection,
just like the rest of us mere mortals.
To Jeni Tennison’s observation that “things recently make me more convinced than ever that the TAG must either provide some direction to the community, and soon, or get out of the way”, my view is that the minimum/sufficient direction is as follows:
- The TAG should provide an unambiguous definition of “resource” to be used by anyone building reasoners. This definition should be concept-centric.
- The TAG should provide a general advisory to anyone publishing linked open data that in the instance they wish their data to be used by consumers for more than simple graph traversal then they need to understand fully, and conform to, the definition of “resource” being implemented in reasoners.
- The TAG should deprecate Cool URIs
I think they should then stand back and let normal evolutionary drivers take care of the rest. It seems unlikely that any organisation whose business cases depend on the type of market-differentiating graph hops made possible by the power of semantic inference is going to get their notion of “resource” mixed up more than once.
