
Daisy Architecture
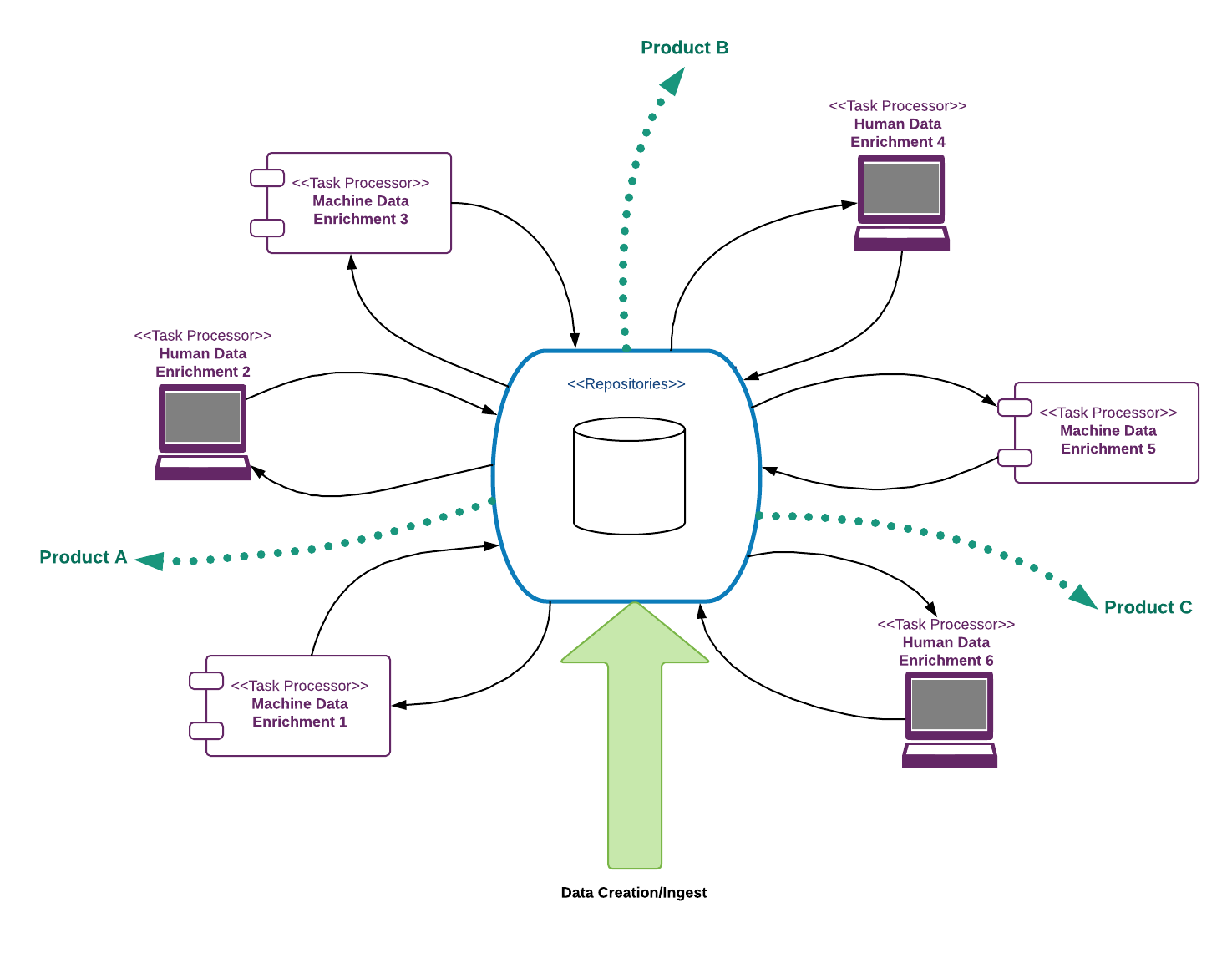
Over the last couple years, one of the more interesting architectural patterns to have emerged on deliveries for our media customers has internally acquired the name ‘daisy architecture’. It evolves as organisations acquire the ability to scale their premium content production processes via the use of machine learning, text analytics and annotation techniques, and then extend the coverage of that tooling over as much of their remaining content geography as possible. In workflow terms, this entails a switch from content production pipelines that are a.) push-based; b.) manual and c.) linear; to content enrichment cycles that are a.) pull-based; b.) automated; and c.) on-demand and iterative:
Enabling factors
The pattern is typically the result of three technical enablers:
- The increasing influence of Kanban on software design, (i.e. principles taken from how applications are delivered and applied to how they work, in particular pull-based systems and queue balancing/optimisation techniques).
- The scaling of automated content analysis and rich metadata creation via text analytics and machine learning.
- The adoption of micro-service architectures, allowing business functions to be recombined much more easily to serve the individual needs of specific product contexts.
1. Kanban
The influence of Kanban techniques not only on the process of application delivery but on the outputs of application design (i.e. on business processes implemented in software) is arguably a return to its roots in some ways. We perceived that as a direct transfer of principles, but what also seems to be going on here is that the influence of Kanban is spreading out of software delivery into business operations more generally (we are definitely seeing increased adoption of pull-based value streams measured via cycle time and queue buffer monitoring) and that is then being reflected back into the styles of software design that are required to support those pull-based business processes.
2. Machine Learning
There has been without doubt an aggressive increase in the use of machine learning and AI techniques within media organisations to automate content metadata creation and indexing (see our machine learning cloud service for a typical example). Critical differences between automated and manual task processing are firstly that automation has essentially negligible operational cost, and secondly it has a larger variability in the quality of its output. This has a major impact on the economics of workflow design. Historically, content production workflows were designed as linear pipelines because every step was manual and therefore costs were within similar boundaries of magnitude. Once certain steps incur negligible cost however, new opportunities open up to process much larger content volumes at basic quality levels. From a brand/product risk management perspective, this then needs to be complimented by quality assurances steps, i.e. manual review. Those manual steps are where the costs are incurred, which is why it is highly desirable for them to do so just-in-time i.e. once product opportunities have been targeted which clearly outweigh that investment.
Interestingly, for these reasons we are seeing a significant impact of automation on changing job roles in this space, but a negligible impact of automation on actual jobs - apart from some impact to very repetitive, rule-based work (i.e. a prime candidate for a machine) that has most often already been outsourced. Instead we are seeing job roles switching from production at lower volumes to the curation of production at higher volumes. This typically takes the form of:
a. Quality Assurance of machine output, the results of which can then be used as ongoing training data to refine machine statistical models.
b. Sampling Tuning. Not all content is equal: the quality of machine output will depend on both its source and its subject area (e.g. the simple factual statements of a football match report will typically be easier for a machine to analyse successfully than an in-depth opinion piece). That means different QA sampling rates will be required for content in different subject areas and from different sources: e.g. new syndication source vs in-house editorial, and those rates will then need to be managed by people over time: e.g. as the new syndication source becomes a trusted partner they will need less manual oversight so the sampling rate should be reduced.
c. Terminology management: to ensure that controlled vocabularies are used to encode the core entities and relationships of the business domain thereby maximising data interoperability across the organisation. (This is one of the core benefits of using domain-driven design to define the information architecture)
3. Micro-services
The adoption of micro-service architectures has unlocked access to discrete units of business functionality, allowing them to be recombined in novel ways according to the emerging needs of new product contexts. This doesn’t mean a return to the dark days of untestable spaghetti service orchestrations in black-box ESBs. Choreography logic should still be pushed into endpoints (or else into a standalone endpoint if justified), but it should be implemented as a strategy pattern – where the content enrichment strategy is determined by a specific product need rather than hardcoded.
Services and Routing
Product-specific service choreography basically means having a routing service that can execute an enrichment strategy which encodes the content requirements of a specific product context (for example: it needs subject classification metadata, time-coded video scene metadata, advertising block-word annotations, etc). Doing this just-in-time however means that you only know the state of the required output, not the input state (as you don’t know which enrichment operations might already have been performed). This has two interesting consequences:
- Routing tends to be both expressed and executed in terms of gap analysis: i.e. perform whatever enrichment operations are required to get content selection C into state P needed by my product.
- Services tend to be partitioned into enrichment services and content search/persistence services, with the latter frequently needing to support terse query semantics that can be either named or URL encoded and passed between other services.
The final point worth mentioning concerns the temptation to implement aggregate AI solutions, i.e. replacing a workflow that is currently 12 manual steps/functions with a single neural network solution or similar. The argument goes that machine systems are fundamentally different from human systems hence there is no need to decompose them into small steps: you can just train from required outputs against known inputs and get rid of all the complexity. The first point to note here is that the complexity isn’t being removed, it’s just being hidden. Moreover, it is being aggressively hidden as anything encoded in a neural network is semantically opaque: it is essentially just set of weightings that produces a desired output, which means there are no conceptually interoperable subcomponents that can be decomposed back out into something actionable by humans if anything starts going wrong. Also error margins will almost certainly be amplified across a monolithic system that has no intermediary review and correction checkpoints. For these reasons our advice is to steer clear of AI monoliths. Instead we recommend you continue modelling your business processes as discrete, atomic functions, and then leave the decision of human vs machine vs human-assisted machine to be an implementation concern only. The key task is to ensure your systems are then designed to allow that decision to be revised according to changing circumstance with minimal operational impact.
The next generation of adaptive businesses will be those that can swap between outsourced, insourced, human, machine and human-assisted machine implementations of their core business functions with minimal impact to their ongoing operational capabilities. That will be the true test of how cohesive and loosely-coupled the service-based architectures of today really are.
