
Case Study: How Data Graphs and AI Auto-Tagging transforms Publishing
The Snap
Tagging content has been a publishing staple for two decades, helping publishers organise content, perform rudimentary content analytics, and also deliver tag based user journeys and content aggregations. In many cases publishers use the tag features built into their CMSs. WordPress and its derivatives are so widely used, yet still have a very weak content tagging capability. This lack of good information management and structured metadata often leads to a tag mess over time, as tags cannot be properly disambiguated, duplicates invariably get created, and journalists apply tags inconsistently. Silver Oliver has written an excellent series of articles on this subject that are worth revisiting.
This is where more contemporary information management technology and AI can be a game changer. I outline below how we have used our own Text AI and Knowledge Graph products to solve these issues, and drastically improve how structured metadata is used at a large global news publisher.
The Back Story
In the context of this project, we were not dealing with a single CMS, but multiple news publications, each with their own publishing technical stack, CMS, mechanism for tagging, and entirely separate tag sets. The ambition was to centralize the metadata used to tag on each publication, and use AI to aid the journalists, essentially raising the consistency level of tagging across news desks, and streamlining and optimising the tagging process. Downstream, this would unlock better user journeys for consumers, better content analytics, and provide for better and more rapid cross-publication innovation.
To achieve this, we integrated:
- Our product Data Graphs to manage a large corpus of the cross-publication tags, constructed as a light-weight knowledge graph of news concepts, including concept types such as People, Locations, Organisations, Events, Brands, Sports teams and athletes, Categories and Topics.
- Our AI Text Classification service, Tagmatic - which predicts the “aboutness” of content by tagging using the concepts managed in Data Graphs, continuously learning on-the-fly as new articles are published.
The Storyline
Our two products Data Graphs and the Text Classification AI work seamlessly together as an ideal solution for an information backbone in the new generation of publishing technology ecosystems.
We move from the legacy pattern of tagging with flat tags, to tagging with well modelled and organised structured data, where each concept we tag with has a globally unique, persistent and durable identifier (a URI / URN), and has its own metadata properties that can be used to provide more information about that concept to help users disambiguate (types, thumbnails, images, descriptions, categories etc) and also provide better user experiences and journeys with these concept tags.
Managing this metadata centrally outside of your CMS provides a number of advantages:
- Your tags are not tightly coupled to one CMS (with respect to identity, structure, access and availability etc) - giving you an easy upgrade path or migration to a different CMS in the future
- The ability to easily use that metadata in other parts of your publishing stack or share with other CMSs. For example, the same metadata can then be used to tag or classify source feeds upstream from content authoring such that external content and your own content are tagged using the same classifications and concepts.
- Decouple the management of the metadata from the CMS, such that a librarian or information specialist takes on that task, leaving your journalists to do what they do best and author content.
To do this, Data Graphs allows the publisher to:
- Create a domain model of their core entities (People, Places, Orgs, Sports, Events, Topics, Content Types, and any other metadata they need to drive their publishing processes and user experiences) and how they prefer to classify and relate these concepts to each other.
- Ensure these concepts are modelled with all the structured data you need for concept disambiguation, categorisation, and concept driven user journeys.
- Easily populate this model with the instances (taxonomies) of this metadata (essentially, publishing reference data) using either the Data Graphs API or CSV Uploaders in the Data Graphs web app.
- Manage that metadata with a dedicated application, with an intuitive user experience.
- Integrate the metadata with any of your business systems using its APIs and Web Hooks, including your CMSs and other data or content stores.
Using machine intelligence to automatically tag concepts and classifications of your articles, also provides a number of advantages:
- It makes the task of tagging and classifying content easy and faster. Many journalists don’t like having to tag their articles, and may not understand the value of tagging well. Because the AI learns from all journalists, and from golden documents, this means the quality level is raised for all authors, and consistency is improved across all news desks.
- The AI can be used to tag content outside of the CMS, completely offloading this task from the journalists - either using a human-in-the-loop pattern (where a totally different person/role validates the quality of the metadata the AI is applying), or in a fully automated mode, for say long tail content where you may not be so concerned about occasional mistakes being made, where the cost of human supervision might exceed the value realised.
- The AI can be used to tag content upstream from your CMS, tagging external feeds (Reuters, AP, Social feeds etc) with the same metadata you apply to your own content. This can deliver much more efficient tooling for the processing of this large content funnel on your news desks.
The Data Language Text Classification AI (Tagmatic) is designed for exactly this task. It is a high-performance scalable service that learns how you classify and tag your content, and then applies metadata to new content that is sent to it for prediction. The service is highly scalable, fully private, and designed to adapt to each publisher’s unique tagging style. Its REST API allows for very easy integration with your CMS and publishing stack, such that it learns continuously on-the-fly, reacting quickly to new concepts that arise in the ever changing window of news.
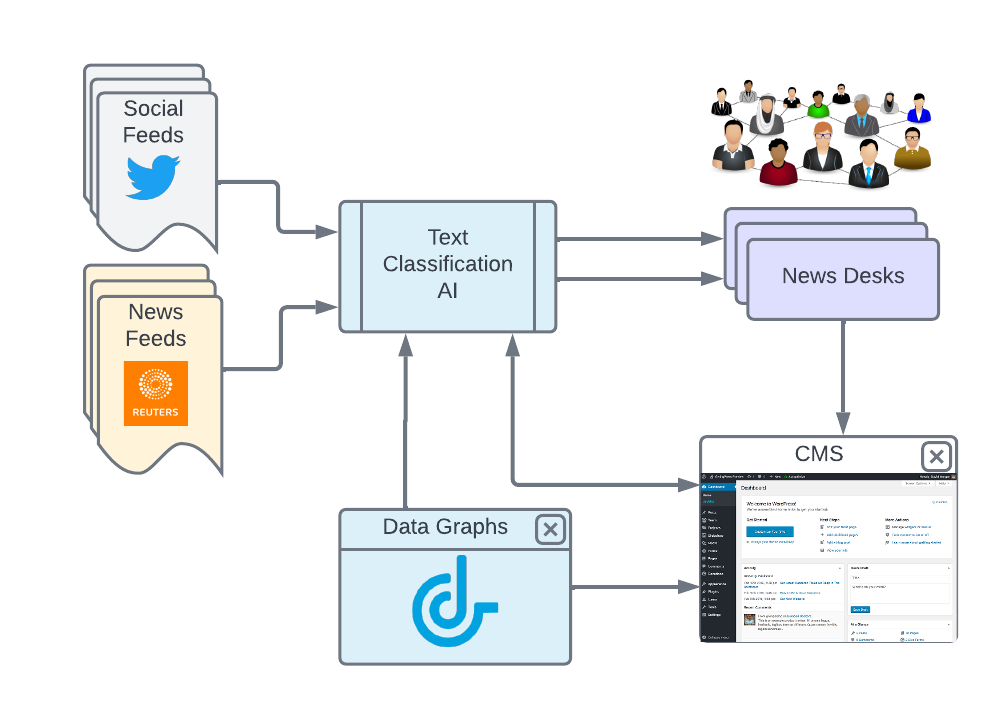
Data Graphs and Tagmatic work seamlessly together, through a dedicated connector, such that when a concept is merged or removed in Data Graphs, Tagmatic automatically adjusts its models’ weights to reflect the new state.
The Explainer
Technically Data Graphs and our Auto-tagging Text AI work together as shown in the diagram below. In this case study a custom WordPress metadata plugin was created that integrated with both the Data Graphs and Tagmatic APIs to provide a human-in-the-loop tagging UI directly in the publisher’s CMS:
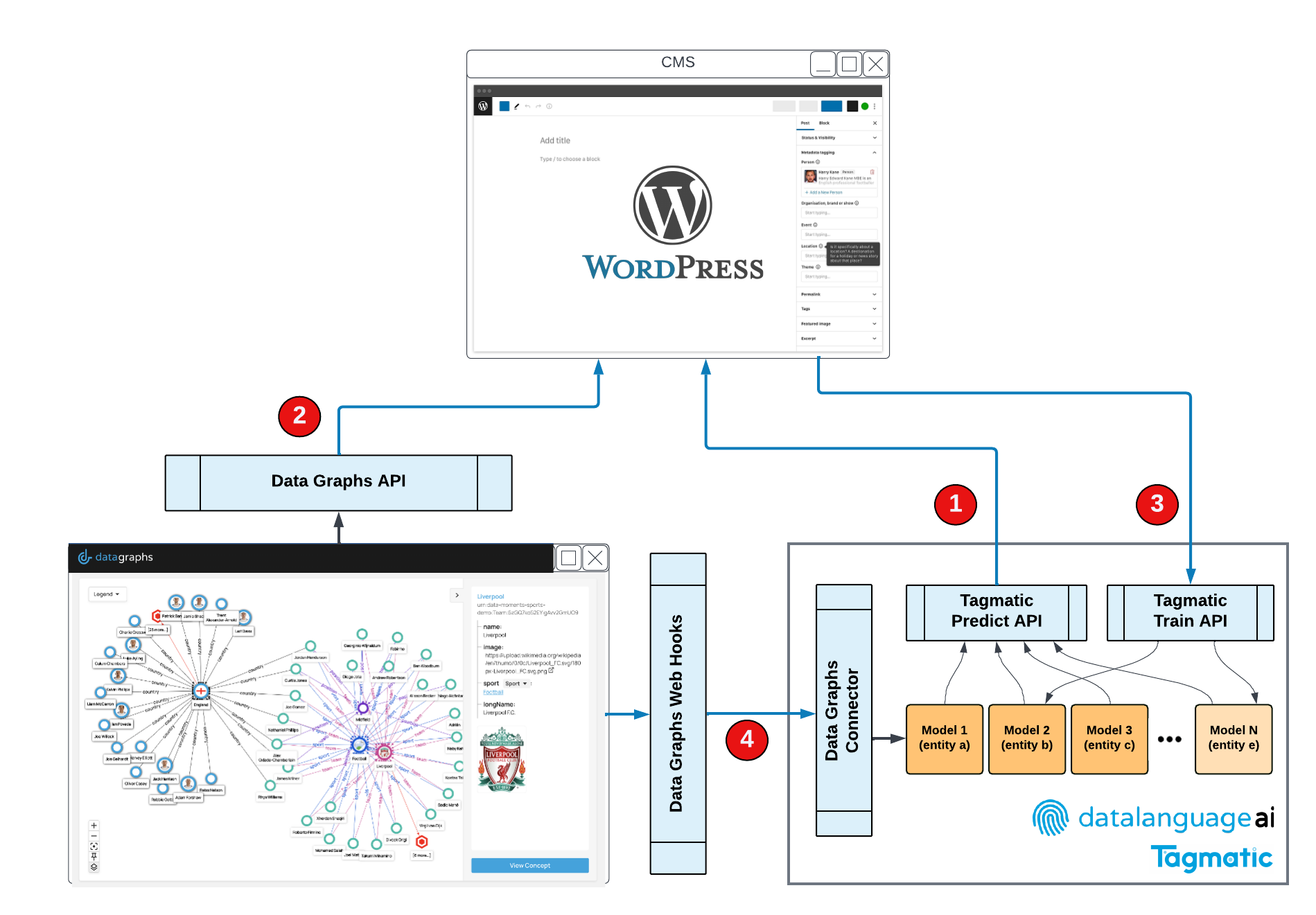
Where:
- The article is sent to the Tagmatic Predict service API to suggest concepts to tag with, and these are presented to the user in the WordPress plugin. The classes of the concepts are used to present these in a tagging template suitable for the type of content being authored (News, Sport, Politics etc). The user can then keep or remove the tags that seem incorrect.
- A user can lookup missing or new concepts in Data Graphs via typeahead/autocomplete widgets in the WordPress plugin by using the Data Graphs Search API
- When the article and metadata is saved / published, WordPress sends the content and tags back to Tagmatic to its Train API, so it can use this for continuous improvement of its prediction models. This allows it to learn brand new tags from their first appearance in an article precluding the need for scheduled long running training cycles, and instead learns on-the-fly.
- If the librarian or information specialist removes a tag concept in Data Graphs, it automatically fires a webhook to the Tagmatic connector, so Tagmatic can disable the classifier model for that concept. If a user merges two concepts in Data Graphs, the connector will trigger Tagmatic to re-point its classifier from the source concept to the target concept of the merge operation - and adjust its weights accordingly.
In the more detailed images below you can see how this WordPress metadata plugin might look, and how a concept is presented to the user with enough information from Data Graphs to correctly disambiguate the tag.
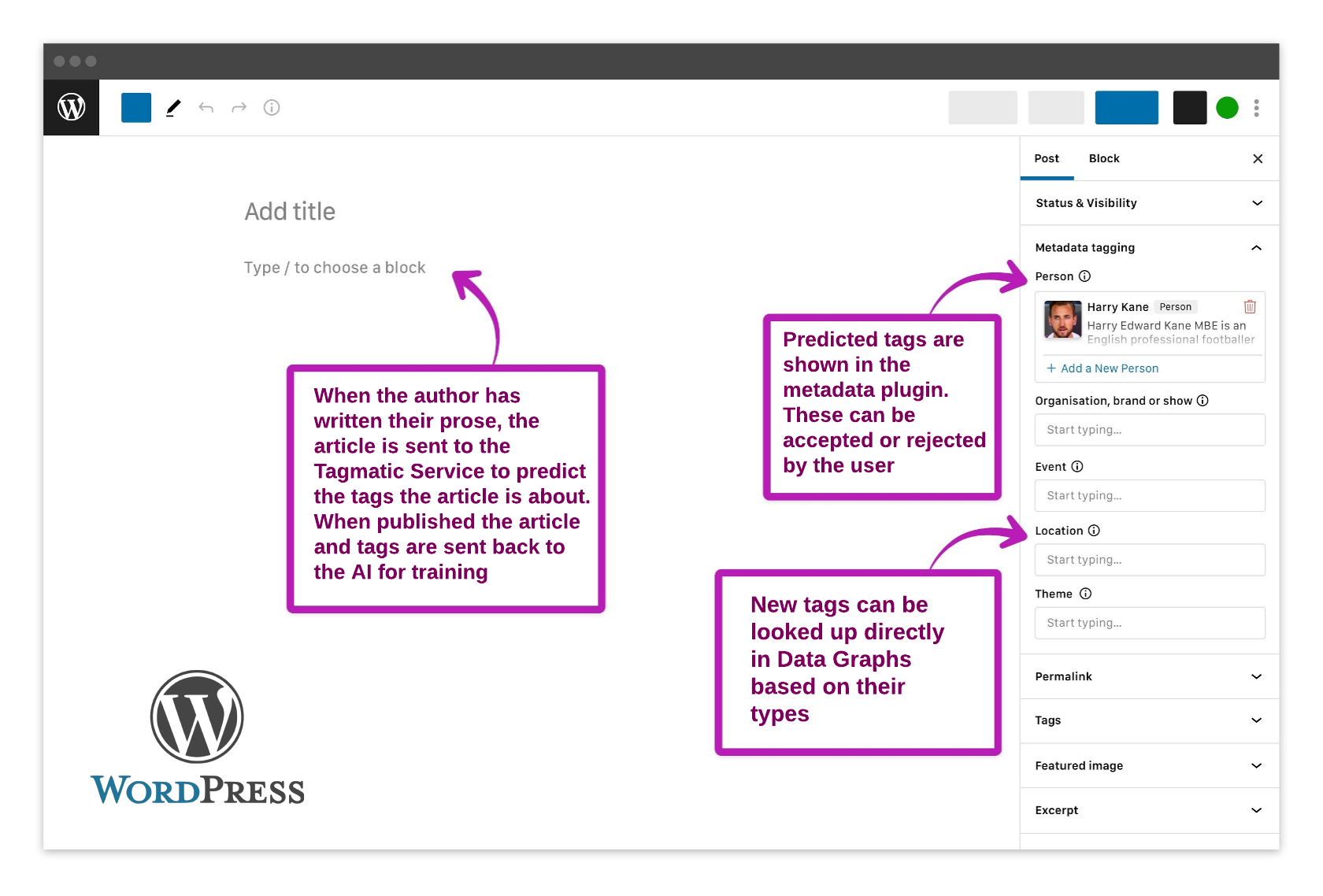
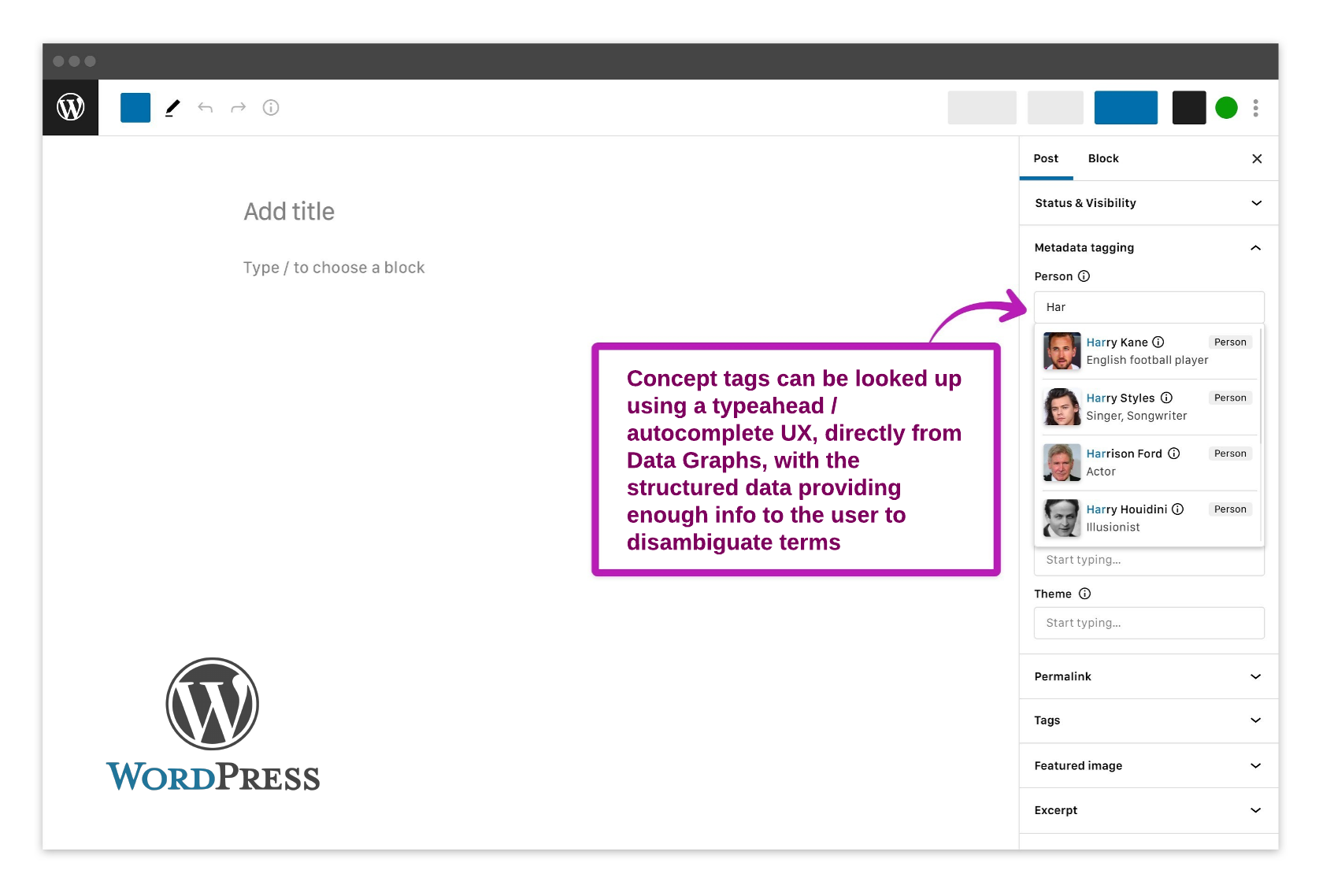
The Finished Article
Bringing these technologies together creates a high-utility information backbone for the modern newsroom, streamlining processes, automating others, and unlocking publishing innovation.
By centralising and decoupling metadata from your CMS, and introducing machine intelligence, you unlock a number of key capabilities:
- Better information and data governance, the importance of which cannot be understated
- The ability to cross-pollinate your reference data across third party content and other internal systems, including both content and user analytics.
- The ability to automate the classification of upstream content feeds with the same metadata, which allows you to scale out the funnel of source material coming into the news desks, and provide better search and discovery capabilities to those journalists.
- Making the journalists job easier - letting them focus more on authoring good content
- The ability to automate the aggregation of content, for example for topic pages, using structured through metadata driven content query APIs
- Let the CMS do what it does best: the authoring and structuring of the content itself
Ultimately, this technology makes tags and concepts management a first class citizen in the publishing stack. No longer just an afterthought inherited from and tightly coupled with the CMS of the day - but something that is built to stay even when the authoring tooling changes, unlocking the true value of your content metadata.
